Interfaces Vol. 4 (2023)

This paper expands on a dated but relevant concept from science and technology studies centered on gender inequality named cyberfeminism. Cyberfeminism is a concept, approach, or movement from the 1990s that sought to increase and solidify women’s representation in science and technology by having them embrace science and technology in their ways. Cyberfeminism peaked in the 1990s but faded in the aughts with Y2K and the dot com boom (Evans, 2016; Paasonen, 2011). The Multimedia Encyclopedia of Women in Today's World entry for cyberfeminism states,
Cyberfeminism refers to a philosophy and community that began in the 1990s along with Third-Wave feminism. Cyberfeminism is dedicated to the intersections of feminism and technology, specifically the Internet. Drawing on postmodern theories of identity and gender, cyberfeminism is a philosophical movement that finds itself at odds with labels and attempts to limit and categorize it as a definitive genre or philosophical set of practices. (Harlow, 2013, p.429)
This definition hints at the vagueness and malleability of the term, which was the intention of founding theorists and practitioners. It also gets at the nuance of the term. The usage of its prefix, cyber, fell out of favor as the Internet and Web became standardized and its suffix, feminism, is open to various interpretations. Cyberfeminisms, is my preferred usage because it implies multiplicity instead of singularity, which is needed when examining the intersections of technology and inequalities.
In this paper, I use cyberfeminism (without the s) only for consistency and historical context. However, as the title of this paper suggests, my preferred term is cyberfeminism(s). I define cyberfeminism(s) as a malleable approach, techno-philosophy, community, and method that aims to address gender inequalities in science and technology but can also be used to address other inequalities that intersect gender, like race, ethnicity, sexual identity, and ability through collaboration, strategy, and creativity. This paper will provide a historical overview of cyberfeminism by surveying its geographical origins, analyzing its critiques, and reviewing its strategies and themes. The scope of cyberfeminism in this paper is limited to self-identified women and girls as early cyberfeminism centered mainly on this group, although there were many debates and discussions against the gender binary due to the fluidity of sexuality and gender online (Chatterjee, 2002; Daniels, 2009; Haraway, 1985; Oksala, 1998; Plant, 1997).
Cyberfeminism: The Beginning
Cyberfeminism has no one definition, so what it is could be defined by anyone who finds themselves fascinated by aspects of it. The malleability of the definition was an intentional choice by early cyberfeminists to appeal to different groups of women (Solfrank, 2017). It gained traction in the 1990s following the increase in usage of the Internet and Web. Both technologies were often conflated as one, despite being separate things (hardware vs. software), as the use of the term “cyberspace” implied they were one entity. With more people outside the government using the Internet and the Web, different groups and cultures were sorting out how to use cyberspace (hereafter meant as a combination of the Internet and Web). Cyberfeminism is closely associated with Donna Haraway, even though she has never self-identified as one. Her influential work, Cyborg Manifesto (Haraway, 1985), can be seen in cyberfeminism’s Australian, European, and North American origins.
Australia: VNS Matrix
VNS Matrix was a four-woman art collective based in Adelaide, Australia, and is often cited for visually conceptualizing what cyberfeminism could be (Evans, 2014; Scott, 2016; Solfrank, 2017). The members included Josephine Starrs, Julianne Pierce, Francesca da Rimini, and Virginia Barratt (Evans, 2014). These women called themselves “power hackers and machine lovers” and declared that they were the “virus of the new world disorder” and “terminators of the moral codes” (Scott, 2016, para.4; Evans, 2014, para. 2). They took a multimedia approach by making cyberfeministic art through computer games, texts, billboards, and video installations (Evans, 2014). Their most well-known “gyne-canonical” text, where many claim the term “cyberfeminism” was named, was their 1991 Cyberfeminist Manifesto for the 21st Century (Evans, 2014; Scott, 2016; Solfrank, 2017; VNS Matrix, n.d.-a.) The manifesto starts with the following,
we are the modern
cunt positive anti reason
unbounded unleashed unforgiving (VNS Matrix, n.d.-a).
The four members wrote it during a stream-of-consciousness writing session, and they noted that it was written in a way that highlighted the conditions of early network culture and cyberspace (Net Art Anthology, n.d.). The session was meant to be “collaborative, plagiaristic, possibly drug-fueled, and pornographic” (Net Art Anthology, n.d., para.2). They used elements from their manifesto to craft an 18-foot billboard with 17 lines of text in Sydney, Australia. It featured half-naked women merged with animal parts and random animated images of DNA with a blue color scheme, as seen in Figure 1 (Evans, 2016; VNS Matrix, n.d.-c). Both the manifesto and images of the billboard were shared through fax, mail, poster, other billboards, and chat rooms, “adopting the techniques of propaganda as an art practice” (Net Art Anthology, n.d., para. 2).

Another popular work from VNS Matrix was their 1995 computer game, All New Gen, as seen in Figure 2. The game was initially titled Game Girl, an intentional play on words to the Game Boy console (VNS Matrix, n.d.-b). This satirical game disrupted gender and technology stereotypes by having the heroines of the game be “cybersluts,” and “anarcho cyber-terrorists” fighting against the phallic power of “Big Daddy Mainframe” with “G-slime—goo shot from weaponized clitorises” (Scott, 2016, para. 6). The game is a great example of the “in your face” sexuality that accompanies cyberfeminism. I argue that VNS Matrix was the most sexual or sexually charged originator of cyberfeminism. They wanted to subvert and defeat stereotypical, misogynistic, and pornographic representations of women by using images and concepts of them owning their sexuality, prowess, and bodies online (Evans, 2014). It made one think beyond the images and was a great way to generate conversations about women online.

Europe: United Kingdom
British philosopher and cultural theorist Sadie Plant was the other individual associated with coining the term cyberfeminism. She is credited with crafting early academic theory on cyberfeminism but received much criticism from cyberfeminist practitioners who focused on art and activism (Paasonen, 2011). Plant (1997) wrote about forgotten women scientists and inventors and highlighted their downplayed historical achievements in her most well-known work, Zeros and Ones: Digital Women and the New Technoculture. British mathematician Ada Lovelace is one of the women inventors she highlights. Lovelace made significant under-appreciated contributions to the computer industry and created the first-ever algorithm in 1843 (Scott, 2016). Charles Babbage, considered the father of the computer, used many of her notes in his work, but she never received the credit she deserved. Her work was overshadowed by her gambling, drinking, and contentious parentage (her father was poet Lord Byron) (Plant, 1997). Plant claims society treats women like the zeros in binary digits and men like the ones (Plant, 1997, pp.34-35). “Woman functions as a hole, a gap, a space, a nothing - that is nothing the same, identical, identifiable … a fault, flaw and lack of absence, outside the system of representations and autorepresenations” (Plant, 1997, p.35) She claims that despite it taking two to make a binary, if a woman is zero, and a man is one, combined they will always make another one, so when can the woman (zero) stand out (Plant, 1997, p.35). Women’s role in science, technology, engineering, and mathematics (STEM) has been precoded not to be important or overshadow the phallic power of the number one in Western reality (Plant, 1997; Sollfrank, 2017). The central argument of her book is that despite male oppression and historical revision, women have always been involved in STEM and had major achievements that many are unaware of. However, some cyberfeminists felt that Plant receives too much credit for coining the term cyberfeminism, despite pulling some of the content for her book directly from VNS Matrix (Paasonen, 2011). Others thought her work was too theoretical and focused too much on comparing women’s history in STEM to men's (Paasonen, 2011). The historical aspects of her book are both her strength and weakness because as thorough as Plant’s review of Western civilization’s disregard for women scientists and inventors is – it does not encompass everything that makes up cyberfeminism. Throughout the book, Plant acknowledges the underappreciated achievements of women in science and technology, but she does not offer any solutions or interventions that align with the liberation of women through science and technology or combating online misogyny.
Europe: Germany
Around 1997, enough women identified as cyberfeminists, that a Berlin-based feminist collective intentionally named the Old Boys Network (OBN) hosted the First Cyberfeminist International held in Kassel, Germany (Solfrank, 2017). The promotional materials for the conference were very “cheeky” and highlighted that it was an event about technology for and about women. Figure 5 shows a “cheeky” flier promoting the conference that used a giant period and a parenthesis to resemble a breast and a nipple with conference logistics at the bottom in a smaller font. 38 women from 12 countries came together to discuss cyberfeminism in person (Scott, 2016). At this conference, they attempted to define cyberfeminism but struggled because of their non-hierarchal and open approach when planning the conference. However, one of the founders of the OBN, Cornelia Sollfrank, described the conference as a “euphoric atmosphere” (Solfrank, 2017, para. 20) where everyone was able to contribute something. These contributions can be seen in one of the results of the conference. Since they were struggling to define cyberfeminism, they decided to define what it was not, which they did through a “provocative anti-manifesto” titled 100 Anti-Theses of Cyberfeminism (Solfrank, 2017; Paasonen, 2011). The title may be a nod to German priest Martin Luther’s provocative Ninety-five Theses against the Catholic Church. Their anti-manifesto featured multiple languages and had humorous and serious suggestions. Some anti-theses included “cyberfeminism is not a fashion statement, cyberfeminism is not an ideology, cyberfeminism is not a fragrance” (Wilding, n.d., p. 10). Their ironic strategy to go a different route and leave the term undefined has been noted as why it never entered the mainstream and had such a short lifespan. “This performative rejection of the political need to define our commonalities indicated a new beginning that later has often been misread as lack of political rigor” (Sollfrank, 2017, para.20). It was both a strength and a weakness to conceptualize cyberfeminism in such a laissez-faire manner.


North America: USA and (Canada)
The North American contributions to cyberfeminism were much more critical of the movements and approaches in other geographies and precipitated its eventual “end.” Influential figures from the U.S. included artist Faith Wilding and scholars Maria Fernandez and Anna Everett. The most well-known Canadian cyberfeminist was the artist, Nancy Patterson. Some in the cyberfeminist community believe that Patterson never received the same acknowledgment as VNS Matrix and Sadie Plant for coining the term cyberfeminism, which she named in her influential 1992 new media art history paper, Cyberfeminism (Paasonen, 2011). In that paper, Patterson focused on gender diversity and cultural subversion in new technologies (Langill, 2009). She emphasized how new technologies can reinforce stereotypes but can also empower marginalized groups to use those technologies to counter those stereotypes (Paasonen, 2011). One can see contemporary examples of Patterson’s argument, particularly in social media campaigns geared towards increasing non-superficial representation and awareness for disadvantaged groups, like in the recent #MeToo and #SayHerName campaigns.
Artist Faith Wilding was a participant-informant at the First Cyberfeminist International and left the conference with many thoughts concerning the privilege of the participants and their ideas (Everett, 2004; Wilding, 1998). She shared these thoughts in a 1998 essay titled, “Where is the Feminism in Cyberfeminism?” for The Feminist eZine (Wilding, 1998). She noticed that some participants hesitated to learn or build on work from the previous waves of feminism despite the cyberfeminist community already using some of their strategies and methods (Wilding, 1998). It included “strategic separatism (women-only lists, self-help groups, chat groups, networks, and woman-to-woman technological training) [and the] creation of new images of women on the Net to counter rampant sexist stereotyping (feminist avatars, cyborgs, genderfusion)” (Wilding, 1998, p.11). The apprehension between learning and building from previous feminist struggles but being eager to work with new technologies was a strange disconnect to Wilding (1998) because combining both was essential to reducing disparities in cyberspace. The historical and cultural context that came with First and Second-wave feminism was downplayed, according to Wilding (1998), as she reported that some even felt uncomfortable identifying as feminists without using the prefix cyber (Paasonen, 2011; Wilding, 1998).
She also cautioned her peers about the rebellious “cybergrrl-ism” aspect of cyberfeminism, which she claimed, “generally seems to subscribe to a certain amount of net utopianism--an "anything you wanna be and do in cyberspace is cool" attitude” (Wilding, 1998, p.8). The “riot grrl” influence from music (punk) and art (zines) seeped into cyberfeminist practice. However, she felt cybergrrl-ism was too focused on the performance and appearance of being a woman or girl in cyberspace and not enough on getting more women and girls in cyberspace (Wilding, 1998). She stated, “being bad grrls on the Internet is not by itself going to challenge the status quo” (Wilding, 1998, p.9). Borrowing language and ideas from feminists that came before her, Wilding (1998) states, “the personal computer is the political computer” to remind those interested in cyberfeminism that technology is inherently political. She remained wary of cyberfeminism without political theory and believed its strength came from the combination of political theory, art, and popular culture.
Wilding (1998) also called out cyberfeminism’s lack of intersectionality and involvement of women in the Global South. “Cyberfeminism presents itself as inclusive, but the cyberfeminist writings assume an educated, white, upper-middle-class, English speaking, culturally sophisticated readership” (Scott, 2016, para.14). White people with computers were overrepresented in early cyberspace, so Wilding wanted cyberfeminism to work more with and for marginalized groups. Wilding attempted to do more with that in real life to address the lack of intersectionality in cyberfeminism through her art and writing. She founded subRosa, a feminist art collective critical of the “intersections of information and biotechnologies on women’s bodies, lives and works” through workshops and performances that still exist today (subRosa, 2013, para. 1; Scott, 2016). In addition, she wrote texts with post-colonial media scholar Maria Fernandez. One of those works includes the post-Y2K text, Domain Errors!: Cyberfeminist Practices, which was the first cyberfeminist text to address intersectionality and post-colonialism (Fernandez et al., 2002).
Cyberwomanism
A scholar not included in early cyberfeminist history but should be is media and film scholar, Anna Everett. Oddly, the sole Black woman who did early scholarly work for cyberfeminism is not acknowledged in its history despite it being a movement geared at increasing representation (Wilding, 1998). Everett (2004) conducted ethnographic research on how Black women utilized cyberfeminism but named it cyberwomanism, an ode to writer Alice Walker’s conceptualization of Black feminism. Everett (2004) conducted a comparative analysis of 1997’s First Cyberfeminist International, and the 1997 Million Women’s March held in Philadelphia, which Black women organized through cyberspace. The event was similar to the Million Man’s March of 1995 but centered on the well-being and self-determination of Black women. The Million Women’s March had about 750,000 thousand participants compared to the 38 attendants at the Cyberfeminist International, but this incredible feat has still not been acknowledged by the community (Everett, 2004, p.1282). Everett notes how Black women used cyberspace to organize for the March despite not all attendees having a computer or internet access. They bypassed this by having folks who worked with computers and the Internet print pages from their website for those who did not have access to either (Everett, 2004). This was done at the peak of the digital divide, so it should be noted in cyberfeminist history (Everett, 2004, p.1282). She mentions that the cyberfeminists in Germany looked at cyberspace as the primary problem. In contrast, the “cyberwomanists” in the US considered it the primary solution (Everett, 2004, p.1280).
Regardless, both approaches were notable achievements for women in cyberspace and showed how non-white women could use cyberspace to advocate for themselves. For marginalized populations, cyberspace can be an open or closed space. Daniels (2009), Gajjala & Oh (2012), Russell (2020), and Wilding (1998) note the critiques of cyberfeminism when it comes to intersectionality, especially regarding race, gender, and sexuality. In her article, Rethinking Cyberfeminism(s): Race, Gender, and Embodiment, sociologist Jessie Daniels (2009) argues that self-identified girls and women engage in practices with internet technologies to transform their material and corporeal lives in complex ways that both resist and reinforce hierarchies of gender and race by using case studies such as pro-ana (pro-anorexia), transgender hormone listservs, identity affirming social networking sites and interworked social movements. These groups with no say in cyberspace or cyberfeminism found ways to use it to affirm, rebel, and procure things for themselves.
Hall (1996) argues that there are two varieties of cyberfeminism. One variety draws from utopic elements of Haraway’s work on the cyborg and focuses on women's liberation through science and technology (Hall, 1996). The second variety is fueled by countering or eliminating male harassment in cyberspace (Hall, 1996). Both varieties use recurring themes that feminist scholars Rosa Braidotti (1996) and Susanna Paasonen (2011) identify as common strategic methods used in texts and artwork by cyberfeminist practitioners and scholars. These central themes are irony and parody/playfulness which are shown in cyberfeminist artwork, performances, text, and media.
Irony
Irony is a rhetorical trope that is often misunderstood. It shows “the contrast or incongruity between how things appear and how they are in reality” (Stanley, n.d, para. 4). Braidotti (1996) notes that the contradictory function of irony is how many cyberfeminists pull their humor. She notes that the combination of irony and (self) humor is shown in many cyberfeminist works. One sees this in OBN’s 1997 anti-theses. Instead of doing what has typically been done to define something, they did the opposite and created a list of things that run counter to how people may think about cyberfeminism. Paasonen (2011) adds that irony is “a cornerstone of cyberfeminism (p.343). While Solfrank (1998) sees the combination of irony, humor, and seriousness as “the quintessential cyberfeminist strategy, a productive tension that makes it possible to join contradictory views” (p.61). Cyberfeminists highlight the “inherent” contradiction of women not being involved in science and technology to get folks to understand the ridiculousness of the idea. Some cyberfeminists caution against using irony, especially when emphasizing diversity and inequality (Passonen, 2011; Solfrank, 2017). In cyberfeminist texts, irony has been used to create distance towards both “cyberculture” and “feminism” in ways that may obstruct, rather than facilitate, critical dialogue” (Passonen, 2011, p.344). For specific intersectional identities, like race and sexual identity, it may not be the appropriate strategy to facilitate change, it may not be ironic, it may be painful.
Parody/Playfulness
Art is the easiest way to see how the politics of parody and playfulness are utilized as a cyberfeminist strategy. Parody, like satire, involves social commentary on political issues, and as Faith Wilding stated, “the personal computer is the political computer,” so the use of parody and playfulness are geared toward making a political statement in cyberfeminism. To cyberfeminists, sex, and technology are also political. The visuals of VNS Matrix’s computer game All New Gen were described as “tongue-in-cheek” (Solfrank, 2017, para.13), and earlier, I described one of the promotional fliers for the First Cyberfeminist International as “cheeky.” As a cyberfeminist strategy, parody is typically associated with women’s sensuality and sexuality. The things that make women “weak,” like their sexual organs, are parodied as empowering. In All New Gen, the heroes do not use guns as weapons but slime from their clitorises. It is an intentionally crude detail that is playful, funny, and ironic. It serves as a reminder of the movement's goals, reducing gender disparities and liberating women through technology. It is seen through the “riot grrl” influence in early cyberfeminism from the zines, marketing materials, and other visual artifacts that constantly remind, tease, and emphasize women’s sexuality through technology. Braidotti (1996) analyzed a riot grrl text and wrote,
In other words, as a female feminist who has taken her distance from traditional femininity and has empowered new forms of subjectivity, the riot girl knows how to put to good use the politics of parody: she can impersonate femaleness in her extreme and extremely annoying fashion (p.8).
This in-your-face approach aims to capture attention by refashioning political issues people are familiar with but tinging them with consistently “cheeky” sexual humor. Braidotti (1996) adds that to use parody to be politically effective in cyberfeminism, it must be grounded.
Figure 5 shows an artistic contribution from VNS Matrix to the art book Cyberfeminism Index (Seu, 2023). This flier’s background image is of a giant clitoris with a space-like color scheme that features three mismatched half-dressed dolls, all of which are missing, obscured, and honed in vaginal areas. The accompanying text is “DNA SLUTS.” The text serves as a reminder that this image plays on the connotation of the word “sluts” by zoning in the dolls’ sexual organs. One would still need more context, especially if one did not find the image in the art book, but the image still grabs your attention and makes one think about the intent or point of this work. The importance of grounding your work when making parody or playful art emphasizing gender inequality should be framed as the central point when creating it. The point of making this kind of disruptive art must be grounded as it should be viewed as something that makes a point and inspires change, as Braidotti (1996) noted.

All in all, the term cyberfeminism may be dated, but its tenets, critiques, strategies, and themes can serve as interventions for contemporary issues of gender inequalities. These issues range from deepfake pornography, virtual sexual harassment, image-based sexual abuse, and more. Many unknowingly use cyberfeminist strategies and concepts. People utilize memes and gifs ironically and playfully to make political statements on social media. Others find community and belonging online based on their marginalized identities, while some subvert and challenge power structures through online and offline activism. In a world where the public is constantly reminded that women can be policed, ridiculed, and misrepresented simultaneously digitally and in real life, we may need a callback to cyberfeminism. This iteration of cyberfeminism must be grounded in diversity and inclusive of other marginalized groups like women of color and nonbinary folks because cyberfeminism can still be a way of liberation and countering misogyny, and it should start with those who remain at the bottom of the digital and real-world hierarchy.
Bibliography
Braidotti, R. (1996). Cyberfeminism with a difference. Futures of critical theory: Dreams of difference, pp. 239-259.
Cassell, J., & Jenkins, H. (Eds.). (2000). From Barbie® to Mortal Kombat: Gender and Computer Games. (MIT press).
Daniels, J. (2009). Rethinking Cyberfeminism(s): Race, Gender, and Embodiment. WSQ: Women’s Studies Quarterly, 37(1), 101–124. https://doi.org/10.1353/wsq.0.0158
Evans, C. L. (2014, December 11). An oral history of the first Cyberfeminists. https://www.vice.com/en/article/z4mqa8/an-oral-history-of-the-first-cyberfeminists-vns-matrix
Everett, A. (2004). On Cyberfeminism and Cyberwomanism: High-Tech Mediations of Feminism’s Discontents. Signs: Journal of Women in Culture and Society, 30(1), 1278-1286. DOI:10.1086/422235
Fernandez, M., Wilding, F., & Wright, M. (2002). Domain errors!: Cyberfeminist practices. (Brooklyn: Autonomedia).
Gajjala, R., & Oh, Y. J. (2012). Cyberfeminism 2.0. P. Lang.
Hall, K. (1996). Cyberfeminism. Pragmatics and Beyond New series, 147-172.
Haraway, D. J. (1985). Manifesto for cyborgs: science, technology, and socialist feminism in the 1980s. Socialist Review, no. 80. pp. 65–108.
Harlow, M.J. (2013). Cyberfeminism. In Stange, M. Z., Oyster, C. K., & Sloan, J. E. (Eds), The multimedia encyclopedia of women in today's world. (Vol 1-4). Retrieved from SAGE Publications, Inc. https://doi.org/10.4135/9781452270388
Langill, C. (2009). Shifting Polarities: Interview with Nancy Paterson. [Interview] Daniel Langlois Foundation Collection, Montreal, Canada. https://www.fondation-langlois.org/html/e/page.php?NumPage=1965
Net Art Anthology. (n.d.). A cyberfeminist manifesto for the 21st Century. Rhizome. Retrieved February 29, 2023, from https://anthology.rhizome.org/a-cyber-feminist-manifesto-for-the-21st-century
Oksala, J. (1998). Cyberfeminists and women: Foucault's notion of identity. NORA: Nordic Journal of Women's Studies, 6(1), 39-47. https://doi.org/10.1080/08038749850167923
Paasonen, S. (2011). Revisiting cyberfeminism. COMMUNICATIONS-EUROPEAN JOURNAL OF COMMUNICATION RESEARCH, 36(3), 335-352. DOI:10.1515/comm.2011.017
Plant, S. (1997). Zeroes ones: Digital women the new technoculture (1st ed.). (New York: Doubleday).
Richard, G. T., & Gray, K. L. (2018). Gendered play, racialized reality: Black cyberfeminism, inclusive communities of practice, and the intersections of learning, socialization, and resilience in online gaming. Frontiers: A Journal of Women Studies, 39(1), 112-148.
Russell, L (2020). Glitch Feminism: A Manifesto. (New York: Verso Books).
Scott, I. (2016, October 13). A brief history of cyberfeminism. Artsy. https://www.artsy.net/article/artsy-editorial-how-the-cyberfeminists-worked-to-liberate-women-through-the-internet
Seu, M. (Ed). (2023). Cyberfeminism Index. (Inventory Press).
Sollfrank, C. (1998). Female Extension. In C. Sollfrank & Old Boys Network (Eds.), First cyberfeminist international (pp. 60 64). Hamburg: OBN.
Sollfrank, C. (2017). Revisiting the Future. Transmediale. https://archive.transmediale.de/de/content/revisiting-the-future
Stanley, H. (n.d.). Irony: Definition, types, and examples. Writer. Retrieved February 3, 2023, from https://writer.com/blog/irony/
subRosa. (2013, February 21). What is subRosa?. https://archive.ph/20130221173356/http://www.cyberfeminism.net/about.html
VNS Matrix. (n.d.-a). The Cyberfeminist Manifesto for the 21st Century. Retrieved March 18, 2022, from https://vnsmatrix.net/projects/the-cyberfeminist-manifesto-for-the-21st-century
VNS Matrix. (n.d-b.). All new gen. Retrieved March 18, 2022, from https://vnsmatrix.net/projects/all-new-gen
VNS Matrix. (n.d.-c). Billboard project. Retrieved from https://vnsmatrix.net/projects/billboard-project
Wilding, F. (1998). Where is feminism in cyberfeminism? https://www.ktpress.co.uk/pdf/vol2_npara_6_13_Wilding.pdf
Vanessa Nyarko (December 2023). “A Callback to Cyberfeminism(s).” Interfaces: Essays and Reviews on Computing and Culture Vol. 4, Charles Babbage Institute, University of Minnesota, 50-61.
About the author: Vanessa Nyarko is a doctoral candidate in Communication Studies at the University of Minnesota-Twin Cities. Her research interests are in emerging technologies, media history, tech policy, and the political economy of media. She specializes in studies of the metaverse, Virtual reality, and reproductions of racism and sexism in digital spaces.
In the present moment, there are numerous discussions and debates about the function and even the possibility of memorization in artificial neural networks, especially in large language models (Tirumala et. al., 2022). A model that has memorized content from its training data is particularly problematic, especially when these models are used for generative tasks. Desirable outputs from generative models are those that closely resemble but do not exactly match inputs. Corporations developing and releasing these new technologies may make themselves vulnerable to plagiarism or theft of intellectual property charges when an output image matches those found in training data. Exceptional performance on natural language processing benchmarks or highly accurate responses to questions from academic and industry tests and exams could be explained by the inclusion of these objects in the training data. “Leaked” private information is also a major concern for text generative models and evidence of such information would create similar liability issues (Carlini et. al., 2021). While deep learning models do not record strings of text or patches of images within the major architectural components—their weights, specialized layers, or attention heads—information from the network can be reconstructed that can reveal sources used as training inputs. This behavior is known as memorization. Memorization is frequently understood to signify a failure of information generalization. Deep neural networks are designed to recognize patterns, latent or explicit, and generalize from the representations of these patterns found within the network—this is why they are called models. Concerns about the leaking of private information are serious but are not the only issues connected with memorization in machine learning; memorization of training data is especially a problem for the testing and evaluation of models. Neural networks are not information storage and retrieval systems; their power and performance are the result of their exposure to many samples from which they learn to generalize. There are different theories of “information retention” in neural networks and the material history of the early implementations of machine learning provides evidence for the ongoing slipperiness of the concept of memory in machine learning.
The concept of memory was used in multiple distinct ways in machine learning discourse during the late 1950s and early 1960s. The interest in developing memory systems during that historical moment was tied up in the relays between three overlapping issues: the status of machine learning systems as brain models, and related, the issue of perception and memory as mutually implicated, and finally the belief that specialized learning machines would be faster than conventional computers. The machines that gave machine learning its name were originally developed as an alternative to general-purpose digital computers. These analog machines needed to sense and store information acquired from input data. The various memory mechanisms proposed during this era functioned like semi-permanent non-volatile storage for these learning machines. They were also the weights used to learn the criteria for classification of input data. They thus played something of a double role in these systems. If the weights were the “programming” for these self-organized systems, then they function as a record of that programming. Serving as both data and instructions, these weights enable what we now call inference on the learned model, which is to say the classification of previously unseen inputs. Memory was not only the persistence of information within the model; it was also used to refer to the nature of the representations stored as information within the weights. Like the contemporary concern with memorization, an exact memory of inputs would mean that the model would likely fail to generalize, which is to say that it was not learning.
In Frank Rosenblatt’s April 1957 funding proposal for the research project known as “Project PARA” (Perceiving and Recognizing Automaton) that would eventually result in the creation of the Mark I mechanical perceptron, Rosenblatt described his recently articulated perceptron rule as not just a method for determining decision boundaries between linearly separable data but also as a way of conceptualizing memory: “The system will employ a new theory of memory storage (the theory of statistical separability), which permits the recognition of complex patterns with an efficiency far greater than that attainable by existing computers” (Rosenblatt, 1957). As a brain model—this was the motivating research paradigm that Rosenblatt would make clear throughout his unfortunately short life—research into machine learning and the perceptron was concerned with using these simulated neural networks to understand more about perception and brain function. While visual perception dominated early research, this area could not be unlinked from a concern with understanding how visual inputs were stored and how memories of previously perceived patterns were compared with new stimuli.
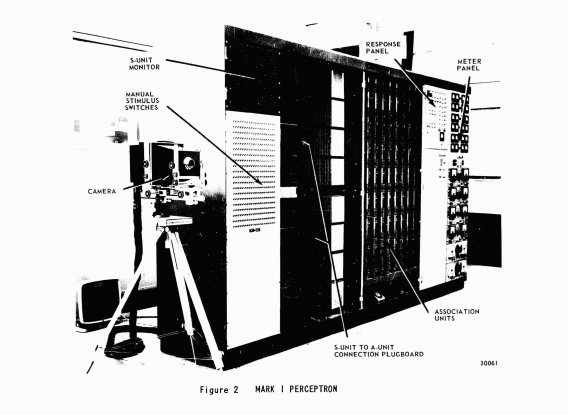
The “Project PARA” proposal outlines Rosenblatt’s architecture. The system would be composed of three layers: the sensory or “S-System,” an association or “A-System,” and finally the response or “R-System.” This architecture was imagined as a mechanical device and Rosenblatt anticipated this material manifestation of his design in all three layers. The “S-System,” he wrote, should be imagined as “set of points in a TV raster, or as a set of photocells” and the “R-System” as “type-bars or signal lights” that might communicate output by “printing or displaying an output signal.” The “A-System” would be the heart, or rather brain, of the perceptron by passing input from the sensors to the response unit by operating on the inputs in combination with pre-determined threshold value. The output from the multiple A-units, Rosenblatt explained, “will vary with its history, and acts as a counter, or register for the memory-function of the system” (Rosenblatt, 1957). References to the material origins of machine learning are scattered throughout the terminology of this field. The weights that are learned from samples of training data are called weights because these were weighted connections between mechanical devices. The A-System provided the Perceptron’s “memory function,” but what it was “remembering” within these weights would be the subject of some debate.
There were a number of other early analog “learning machines” that confronted the same problems encountered by Rosenblatt. After being exposed to the Perceptron while working as a consultant in the U.S., Augusto Gamba, a physicist at the University of Genoa in Italy created his own device known as the PAPA (derived from the Italian rendering of Automatic Programmer and Analyzer of Probabilities). Like Rosenblatt’s Perceptron, the PAPA combined memory and the statistical method for determining decision-making criteria:
A set of photocells (A-units) receive the image of the pattern to be shown as filtered by a random mask on top of each photocell. According to whether the total amount of light is greater or smaller than the amount of light falling on a reference cell with an attenuator, the photocell will fire a “yes” or “no” answer into the “brain” part of the PAPA. The latter is simply a memory storing the “yes” and “no” frequencies of excitation of each A-unit for each class of patterns shown, together with a computing part that “multiplies” or “adds logarithms” in order to evaluate the probability that an unknown pattern belongs to a given class (Borsellino and Gamba, 1961).
Gamba’s PAPA borrows the name “A-unit” from Rosenblatt’s idiosyncratic nomenclature (one of the reasons the PAPA has become known as a “Gamba perceptron”) for the Perceptron’s second layer, its hidden layer, although in Gamba’s architecture, the device’s “memory” is not found in the association layer but in the final “brain” unit.
The relation between the machine’s accumulated weights to the input data was an open problem and several different theories were used to explain and interpret the meaning of these values. For some historians of machine learning, the simplified mathematical model of a neuron proposed by Warren S. McCulloch and Walter Pitts has been assumed to be the major inspiration and basis for many working on the first neural networks (McCulloch and Pitts, 1943). While these McCulloch-Pitts neurons (as they are called) were incredibly influential, it was another theorical account that yoked together a model of perception and memory that would influence the architecture of the most important early neural networks. This was the decidedly non-mathematical work of Donald O. Hebb, a Canadian psychologist. Hebb’s The Organization of Behavior, proposes a theory that seeks to reconcile what otherwise appeared as two distinct accounts of memory by answering the question of “How are we to provide for perceptual generalization and the stability of memory, in terms of what the neuron does and what happens at the synapse?” (Hebb, 1949). Perceptual generalization is the idea that people can learn to generalize from just a few examples of a wide range of objects. As Hebb puts it, “Man sees a square as a square, whatever its size, and in almost any setting” (Hebb, 1949). The stability of memory was rooted in evidence of a persistent connection or association between particular stimuli and a set of neurons. Hebb theorized a solution to this impasse with the idea of locating (in terms of neurons) independent patterns of excitation. This idea was of obvious utility to machine learning researchers wanting to develop techniques to recognize objects like letters no matter where they appeared, for example, shifted to the left or the right, when projected on a two-dimensional set of sensors called the “retina.”
In an article appearing in 1958, Rosenblatt examined one theory of perception and memory that suggested that “if one understood the code or ‘wiring diagram’ of the nervous system, one should, in principle, be able to discover exactly what an organism remembers by reconstructing the original sensory patterns from the ‘memory traces’ which they have left, much as we might develop a photographic negative, or translate the pattern of electrical charges in the ‘memory’ of a digital computer” (Rosenblatt, 1958). Instead of memorizing inputs, Rosenblatt explained, the Perceptron implemented Hebb’s theory of learning and separated learned patterns from their exact inputs. “The important feature of this approach,” Rosenblatt wrote, “is that there is never any simple mapping of the stimulus into memory, according to some code which would permit its later reconstruction” (Rosenblatt, 1958). In these relatively simple machines and simulated networks, the association units might record the history of inputs as a collective representation, but they could not reproduce individual memorized inputs. For Rosenblatt, this was a sign of the success of the Perceptron; it demonstrated the practicality of Hebb’s theory by implementing a memory system in the form of weights that could be used for distinguishing between classes of data without memorizing distinct inputs used to train the network. This was also Rosenblatt’s grounds for differentiating the Perceptron from mere pattern matching: techniques developed contemporaneously with the Perceptron implemented databases of templates and accomplished pattern matching by memorizing and matching input samples to entries in a database (Dobson 2023).
Research on analog memory units connected two of the major sites in the development of machine learning: Rosenblatt’s lab at Cornell University in Ithaca, New York and Stanford Research Institute at Stanford University in California (Stanford University would shortly divest itself of the laboratory, which would then become known as SRI International). While Rosenblatt’s Mark I Perceptron is the best known of the early machines of machine learning, SRI had developed its own series of devices, the MINOS and later the MINOS II. While SRI’s first projects implemented the Perceptron, researchers would later develop an alternative learning rule. SRI’s MINOS project was a platform for evaluating different sensing and preprocessing techniques. George Nagy, a Hungarian-born computer scientist, worked with Rosenblatt at Cornell while a graduate student in electrical engineering; memory devices for neural networks became the subject of his dissertation and related research. Nagy worked with others in Rosenblatt’s Cognitive Systems Research Program (CSRP) group to design and construct a second-generation device called the Tobermory.
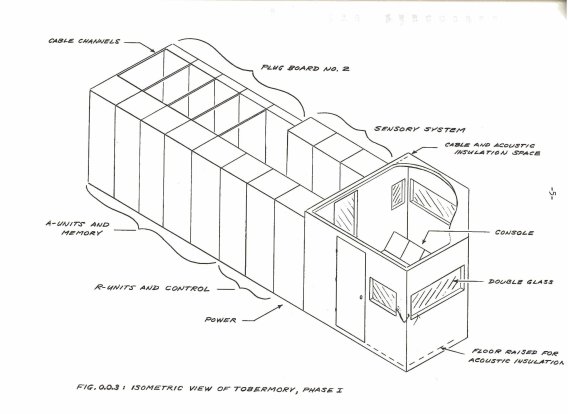

The Tobermory took its name from a short story by Saki (H. H. Monroe) that featured a talking cat. As its name suggests, it would be a “phonoperceptron” and designed for audio input. Nagy’s dissertation, defended in 1962, was titled “Analogue Memory Mechanisms for Neural Nets” and examined different possible designs for analog memory devices. Some of the existing options examined by Nagy included more experimental electro-chemical devices such as electrolytic integrators and solions and novel but difficult to use at scale film-based photochromic devices using slide projectors. Nagy settled on what was known as the “magnetostrictive read-out integrator,” a device suggested by SRI’s Charles A. Rosen. This was the tape-wound magnetic core memory device employed by the MINOS II and initially designed by SRI staff member Harold S. Crafts (Brain et. al., 1962). It also had the advantage of sharing features with the core memory used in conventional digital computers. The labor-intensive production of these memory devices, as Daniela K. Rosner et. al. argue, is one of several important sites of “hidden, feminized work” involved in the creation of mid-century computing (Rosner et. al., 2018). Addressing his selection of a tape-wound device for the Tobermory, Nagy wrote: “The chief virtue of the electromechanical integrator consists of its inherent stability. The ‘weight’ of a given connection is represented by a mechanical displacement, hence it is not subject to variation due to ambient changes or fluctuations in power supply level” (Nagy, 1962). Many existing analog alternatives, as Nagy notes in his survey, were subject to rapid decay, error, and sometimes were difficult to reinitialize or to erase previously stored values.
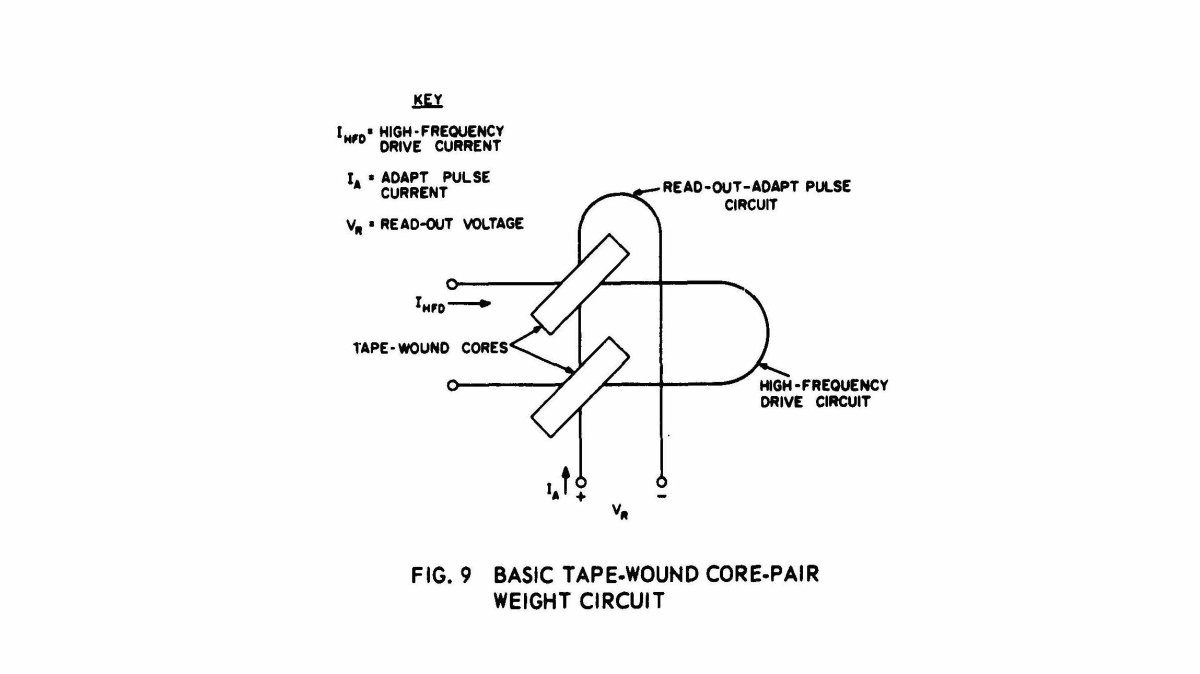

Despite the ongoing research and development of analog learning machines with memory devices during this period, many researchers were simultaneously implementing neural networks as simulated machines on conventional digital computers. In their justification for building a learning machine, the SRI MINOS team explained what they saw as the deficiency of digital computers: “Their major function in the present line of research is to simulate the performance of machine concepts which might be mechanized in some form which would be efficient (smaller, faster cheaper, etc.). The general-purpose digital machine thus appears as a research tool rather than as a final device for pattern recognition” (Brain et. al., 1960). In these simulations, the weights were stored in regular core memory during training and evaluation and persisted in various offline storage systems. The simulation of learning machines was necessary at the beginning of machine learning while engineers worked to construct analog machines and find appropriate memory devices, but this paradigm stuck as digital computers increased in speed and became easier to program and use. The appeal quickly became apparent to researchers. In an article summarizing his research into analog memory devices, Nagy speculated that advancements in digital computers might soon render analog memory obsolete. “In principle,” he wrote, “any pattern recognition machine using weighted connections may be simulated on a binary machine of sufficiently large capacity” (Nagy, 1963a). Specialized hardware for machine learning, although now fully digital and instrumented with layers of software, returned in the late 1980s and early 1990s during the high-performance massively parallel computer boom. Today, costly clusters of high-density graphical processing units (GPUs) and tensor processing units (TPUs) are being deployed to train very large models although these also execute software simulated learning machines.
Early machine learning was primarily directed toward the discrimination and classification of visual data. These models worked with highly simplified representations of images. They were not trained to generate new images. Today’s deep learning models in computer vision and the extremely popular Transformer-based large language models are now routinely used in generative applications. The size of these models combined with these new uses (themselves a function of model size), has prompted a reconsideration of the memory issue. The assumption that patterns of activation generalize, as Hebb theorized in biological models, seems to be under pressure when applied to understanding the operation of artificial neural networks with billions or more parameters. There is strong evidence that large language models are memorizing examples from their training and that this behavior is more likely in large models (Carlini 2021). The retention of this information suggests that these patterns can be mapped. Research into the interpretability of deep learning models has discovered some of these patterns and demonstrated that sets of neurons can be edited to alter the model’s predictions (Meng et. al., 2022). This line of inquiry returns us to lingering important questions about the relation between learning and memory, the differences between generalization and memorization, and the location of memory in neural networks that were also present at the founding of the field of machine learning.
Bibliography
Borsellino, A., and A. Gamba (1961). “An Outline of a Mathematical Theory of PAPA,” Del Nuovo Cimento 20, no. 2, 221–231. https://doi.org/10.1007/BF02822644.
Brain, Alfred E., Harold S. Crafts, George E. Forsen, Donald J. Hall, and Jack W. Machanik (1962). “Graphical Data Processing Research Study and Experimental Investigation.” 40001-PM-60-91.91(600). Menlo Park, CA: Stanford Research Institute.
Carlini, Nicholas, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, et al. (2021). “Extracting Training Data from Large Language Models.” In Proceedings of the 30th USENIX Security Symposium. 2633–2650.
Dobson, James E. (2023). The Birth of Computer Vision. University of Minnesota Press.
Hay, John C., Ben E. Lynch, David R. Smith (1960). “Mark I Perceptron Operators’ Manual (Project Para)” VG-1195-G-5. Cornell Aeronautical Laboratory.
Hebb, Donald O. (1949). The Organization of Behavior: A Neuropsychological Theory. John Wiley and Sons.
McCulloch, Warren S., and Walter Pitts (1943). “A Logical Calculus of the Ideas Immanent in Nervous Activity.” Bulletin of Mathematical Biophysics 5, 115–33.
Meng, Kevin, David Bau, Alex Andonian, and Yonatan Belinkov (2022). “Locating and Editing Factual Associations in GPT.” Advances in Neural Information Processing Systems, 35, 17359-17372.
Nagy, George (1962). “Analogue Memory Mechanisms for Neural Nets.” PhD diss. Cornell University.
Nagy, George (1963a). “A Survey of Analog Memory Devices.” IEEE Transactions on Electronic Computers EC-12, no. 4: 388–93. https://doi.org/10.1109/PGEC.1963.263470.
Nagy, George (1963b). “System and Circuit Designs for the Tobermory Perceptron,” Cognitive Research Program. Report No. 5. Ithaca, NY: Cornell University.
Rosenblatt, Frank (1962). “A Description of the Tobermory Perceptron.” Cognitive Research Program. Report No. 4. Collected Technical Papers, Vol. 2. Edited by Frank Rosenblatt. Ithaca, NY: Cornell University.
Rosenblatt, Frank (1957). “The Perceptron: A Perceiving and Recognizing Automaton (Project PARA).” Report 85-460-1. Cornell Aeronautical Laboratory.
Rosenblatt, Frank (1958). “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain.” Psychological Review 65, no. 6: 386–408. https://doi.org/10.1037/h0042519.
Rosner, Daniela K., Samantha Shorey, Brock R. Craft, and Helen Remnick (2018). “Making Core Memory: Design Inquiry into Gendered Legacies of Engineering and Craftwork.” In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems (CHI '18). ACM. https://doi.org/10.1145/3173574.3174105.
Tirumala, Kushal, Aram Markosyan, Luke Zettlemoyer, and Armen Aghajanyan (2022). “Memorization without Overfitting: Analyzing the Training Dynamics of Large Language Models.” In Advances in Neural Information Processing Systems 35. Edited by S. Koyejo et. al. 38274-38290. Vancouver, Canada: Curran Associates.
James E. Dobson (June 2023). “Memorization and Memory Devices in Early Machine Learning.” Interfaces: Essays and Reviews on Computing and Culture Vol. 4, Charles Babbage Institute, University of Minnesota, 40-49.
About the author: James E. Dobson is assistant professor of English and creative writing and director of the Institute for Writing and Rhetoric at Dartmouth College. He is the author of Critical Digital Humanities: The Search for a Methodology (University of Illinois Press, 2019) and The Birth of Computer Vision (University of Minnesota Press, 2023).

Artificial Intelligence (AI) has been shown time and time again to be a remarkable engine for codifying and accelerating inequality. Popular news media is literally littered with examples of AI gone wrong. Mortgage software has been found to recommend better interest rates for white borrowers (Bartlett et al.). Criminal justice AIs are more likely to recommend denial of parole for people of color (Benjamin). And all manner of bias has been found in search engine results (Noble). In each of these cases, the desire to develop and sell transformative new technologies got in the way of making fair and equitable systems. As a result, many in AI are looking for a better way. In her 2016 Weapons of Math Destruction, Cathy O’Neil (2017) argued that the future of AI needed a better “moral imagination.” AI and technology developers need “to explicitly embed better values into our algorithms, creating Big Data models that follow our ethical lead.” Since then, “ethical AI” has become an explosive area of investment and development.
There has been a proliferation of initiatives in industry, nonprofit, academia, and occasionally government—all devoted to better AI. We cannot really say that we are short on moral imagination at this point. In fact, I would go as far as to say that we are confronted by a dizzying array of competing moral imaginations. Different approaches to AI’s moral future vie for attention, leaving technologists with an expansive menu of options. But like the items on any menu, not all are of equal nutritive (moral) value. There’s good reason to believe that much of so-called Ethical AI is little more than window dressing (Burt). It’s handwaving at a vision of fairness that comes second to innovation and profit. There’s also good reason to think that even the best of intentions will not lead to ethical outcomes. This last issue is the focus of this piece. Much has been written about Ethical AI that’s little more than marketing. I want to think about how new technology designed to address a clear and obvious ethical need often falls short. In so doing, I reflect on a few recent attempts to develop AI for better pain medicine.
The Pain Problem
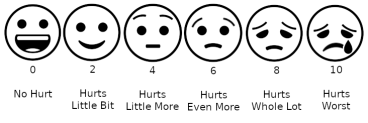
On a scale of 1-10, how much pain do you feel right now? This simple question, asked millions of times a day throughout the world, is state-of-the-art in pain measurement. The Numeric Pain Rating Scale (NPRS) and its cousin, the Visual Analog Scale (VAS)—sketches of progressively sadder smiley faces—are the primary ways that doctors assess pain. NPRS and VAS are low tech solutions that assist with the practice of pain management. Importantly, they do not really measure pain in any meaningful sense of the word. Rather, they help patients assign numbers to daily experiences and those numbers guide treatment. If your shoulder used to hurt at level 6, but daily stretching makes it hurt at level 3, we know that physical therapy is working.
The International Association for the Study of Pain (IASP) defines pain as “An unpleasant sensory and emotional experience associated with, or resembling that associated with, actual or potential tissue damage.” According to the best scientific minds who study the topic, being in pain does not require you to have an underlying physical injury. Have you ever winced when you saw someone else touch a hot stove? This is one reason why “potential” is such an important word in the IASP’s definition. You are in pain when you touch a hot stove, and you are in pain when you see someone touch a hot stove. Similarly, the same injury (when there is one) doesn’t cause the same pain in every person. Think about athletes who finish a competition on a broken leg, and only realize it after crossing the finish line. There was no pain until the situation changed, and then there was incredible pain. All of this is why the IASP’s definition of pain comes with a critically important note: “A person’s report of an experience as pain should be respected.”
Unfortunately, despite this recommendation from the IASP and even though the NPRS and VAS scales are the gold standard approach to pain management, the inability to directly measure pain is a regular complaint among healthcare providers. In my conversations with pain management doctors, many have expressed a strong desire for actual pain measurement. An interventional anesthesiologist I spoke to expressed frustration that he didn’t “have a way of hooking someone up to a pain-o-meter” (Graham, 2015, 107). Likewise, an orthopedist complained that “one of the first things those concerned will admit [is] there’s no algometer, no dial on somebody’s forehead. As long as you can’t read it out, you have to rely on the patient’s report” (Graham, 2015, 121). This desire for objectivity combined with the common denigration of patient reports as “merely subjective,” creates a situation where bias often runs amok in pain medicine. Increasingly, AI is being offered as a possible solution for such systemic inequities. In the context of pain management specifically, AI developers are working on what they hope will be that missing “dial on the forehead.”
Trust and Bias
Unfortunately, doctors don’t always trust what patients say about their own pain. Part of this has to do with that drive for objectivity. Part of this has to do with how we’ve responded to the opioid epidemic in this country. And part of it has to do with bias. A 2016 survey of medical trainees found that 73% believed at least one false statement about race-based biological differences (Hoffman et al). Among the most striking statistics was the fact that 58% believed that Black skin is thicker than white skin. This false belief and others like it have been traced directly to inequalities in pain management. Physicians routinely underestimate patient pain across patient groups, but the racial differences are striking.
Doctors are twice as likely to underestimate Black pain (Staton et al). As a result, Black patients are less likely to receive pain medication, and when they do, they routinely receive lower quantities than white patients. As these disparities are increasingly recognized by the medical community, recommendations for improvement tend to center around a mix of implicit bias training and increased reliance on more “objective” diagnostic technologies. The American Association of Medical Colleges, for example, recommends that in addition to implicit bias training, clinical guidelines should “remove as much individual discretion as possible,” and researchers should “continue the search for objective measures of pain” (Sabin).
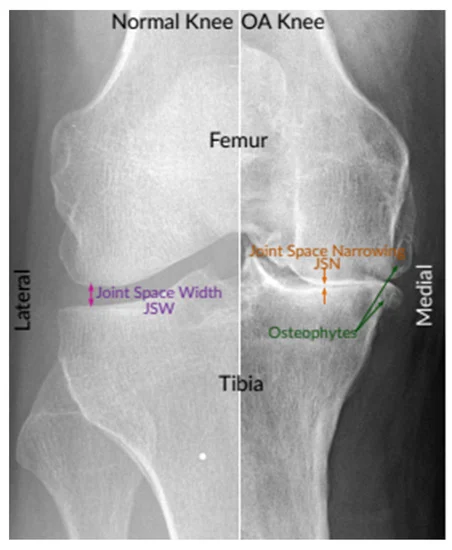
Despite AI’s history of bias, it is frequently justified on the basis of its mathematical objectivity. Combine that with increasing investments in Ethical AI, and it creates the perfect environment for algorithmic pain measurement. And so, the developers of the new algorithmic pain prediction (ALG-P) system hope it will both provide more objective pain measurement and lead to reduced clinical biases (Pierson et al). Working with a diverse population of osteoarthritis of knee patients, the researchers trained the ALG-P to try and match patient reports. That is, they took X-rays of knees and linked those X-rays to each patient’s NPRS score, and the ALG-P system learned to identify certain patterns in the images that would predict NPRS values. Next, the study team compared ALG-P estimates of pain severity with those of the preexisting industry standard clinical decision tool, Kellgren–Lawrence Grade (KLG). The KLG, which was developed and validated on a predominantly white British population in 1957, guides human evaluation X-rays for osteoarthritis of the knee. ALG-P was 61% more accurate in estimating patient pain than the KLG. Importantly, however, while the ALG-P reduces the frequency and magnitude of racial disparities, it does not eliminate them. So, if a Black patient had a true pain level of 8, a doctor using KLG might estimate the pain at level 6, and one using the ALG-P might estimate it at a 7.
At first glance, ALG-P lives up to some of the best recommendations for Ethical AI. One common recommendation for better AI is to ensure that training data is labeled by members of the communities who will be most affected by the system and its use. A pervasive problem in pain medicine is that physicians tend to believe their own estimates of patient pain over those from patient reports. By training ALG-P on labeling data from patient report, the developers artfully sidestep this issue. In an interview with the MIT Technology Review, one of the study authors, Ziad Obermeyer, highlighted this more just approach as central to the study (Hao). Ultimately, both the study itself and some of the related media coverage indicate a hope that the availability of these data might encourage self-reflection leading to reduced clinical biases. As the study points out, “cooperation between humans and algorithms was shown to improve clinical decision making in some settings.” The MIT Technology Review article is even more enthusiastic, suggesting that “AI could make health care fairer—by helping us believe what patients say.” However, living up to one principle of Ethical AI does not necessarily assure that a given AI leads to a more ethical world.
Now, I have a few significant concerns about ALG-P. First, if we think back to the IASP definition of pain, it’s not all that surprising that the AI only leads to a 61% improvement. ALG-P looks at knee X-rays, physical features, and has no access to the psychological state of patients. We’re already missing a huge component of what it means to be in pain if we’re not including the psychological dimension. Also, as a researcher with longstanding interests in pain medicine, I am getting a powerful sense of déjà vu here. Doctors suddenly “trusting” patients when a new technology comes along and “proves” those patients right is becoming an all-too-familiar narrative. Almost 20 years ago, the case du jour was fibromyalgia—a chronic widespread bodily pain condition believed to be caused by difficulties regulating certain nerve signals. Fibromyalgia disproportionately afflicts women, another group many doctors seem to have trouble believing. But twenty years ago, then-recent advances in neuroimaging (PET, fMRI) were able to identify differences in how some people’s brains process certain stimuli. With “objective” technological verifications, doctors started to “trust” their patients.
Now, for many, this version of “trust” does not sound much like genuine trust. If trust is only extended to some patients when what they say is verified through technological “objectivity,” then there is no actual trust at all. What’s more, the average cost of a PET scan in 2020 was just over $5,000 (Poslusny). Even if insurance is reimbursing theses costs, that is a pretty steep fee for “trusting” women in pain. It is not yet clear if ALG-P will be used broadly and if so, how much will it cost patients? But if it’s anything like other computational imaging techniques, it could be pretty expensive for a product that offers around a 61% improvement. This is all the more problematic, of course, given that following IASP guidance and believing Black patients would lead to substantially more improvement while having the benefit of being free.
All-in-all, I have some pretty serious reservations about the extent to which this is an ethical addition to the practice of pain medicine. Importantly, this does not mean I think it’s impossible to make Ethical AI. The case of ALG-P suggests that it takes a lot more than a recognized injustice and a desire to do good in the world to ensure that a new system actually leads to ethical outcomes. Doing so requires more than just new technologies. This is another way of saying that an AI just isn’t going to fix inequality. AIs might be useful as part of a comprehensive approach that includes technical solutions, targeted education, and appropriate regulation. One of the biggest risks of the tech fix is that it will be understood as a “fix.” Maybe ALG-P is a good idea as a stopgap for those patients who are in pain and undertreated right now. But the long-term work toward justice has to continue while band-aid technologies offer partial improvements today.
Beyond the ‘Ethical’ Tech Fix
Ultimately, ALG-P is a textbook example of Ethical AI in a clinical context. Ethical AI tends to embrace a bias toward action. The ethical vision is grounded in the presumption that companies will build things. Thus, governance solutions and interventional technologies alike are engineered to guide (rather than prevent) that action. For the most part, this kind of interventional Ethical AI focuses on technologically engineered solutions to algorithmic bias. For example, one of the canonical works of Ethical AI proposes the following definition of anti-classification in ethical AI:
d(x) = d(x') for all x, x' such that xu = x'u (Corbett-Davies and Goel)
In English, “anti-classification” is largely a matter of not including identifying characteristics (including ethnic data) in AI systems. Of course, as many in critical algorithm studies have pointed out, the complex effects of systemic racism can create surrogate data points for race, such as zip code, which blunt a narrower approach to anti-classification. Although ALG-P was not developed in a corporate context, its underlying logics are remarkably similar to what we see in those contexts. In recent years, IBM, Facebook, and Google have all deployed new computational libraries designed to detect bias or engineer fairness in their algorithms. (IBM; Gershgorn; Google). Technologically oriented solutionism is precisely what allows some areas of Ethical AI to offer an apparently ethical intervention that is still ultimately subordinated to the dominant market logics of the corporation. In much the same way, ALG-P is an act of Ethical AI. To be sure, it is not situated in a corporate context, but it ultimately offers a tech fix that subordinates emancipatory aims to long-dominant clinical logics.
I’m certainly not the first to suggest that technologists need to think just as much about if they should act and when they should act, not just how they should act. There’s a massive cross-sector precautionary literature out there devoted to these kinds of questions. Inspired by that kind of thinking, I close this essay by considering how Ethical AI in healthcare contexts might address precautionary concerns in the face of ongoing harm to marginalized populations. Specifically, I suggest that those who wish to offer technological solutions to health inequity should, at the very least, address the following questions.
- Is the proposed intervention likely to substantially address an unmet or under-met community need?
- Have members of the communities most likely to be affected by the intervention been substantively involved in project conceptualization, putative benefits, risk assessment, data curation, and training set labeling?
- Does the project team have a robust plan for evaluating unintended consequences during design, development, testing, and distribution?
- Does the project team have a robust plan for supporting long-term community-centered justice-oriented initiatives in this area?
If the answer is not a resounding “yes” to all of these questions, then precaution (as opposed to intervention) is almost certainly the way to go. However, in the context of a robust community-led approach to development, then it may be appropriate to work at developing temporary technological fixes. That last question, however, is key. One of the biggest risks of the tech fix is that it will be understood as a “fix.” If healthcare is to work at developing and deploying band-aid technologies offering partial improvements in care, then the long-term community-led work of social justice has to continue and eventually replace those temporary technological scaffolds.
Bibliography
Bartlett, Robert, et al. “Consumer-Lending Discrimination in the FinTech Era.” Journal of Financial Economics, vol. 143, no. 1, pp. 30–56. ScienceDirect, https://doi.org/10.1016/j.jfineco.2021.05.047.
Benjamin, Ruha. (2019). Race after Technology: Abolitionist Tools for the New Jim Code. Polity, https://www.politybooks.com/bookdetail?book_slug=race-after-technology-abolitionist-tools-for-the-new-jim-code--9781509526390.
Burt, Andrew. (2020). “Ethical Frameworks for AI Aren’t Enough.” Harvard Business Review, 9 Nov. hbr.org, https://hbr.org/2020/11/ethical-frameworks-for-ai-arent-enough.
Corbett-Davies, Sam, and Sharad Goel. (2018). The Measure and Mismeasure of Fairness: A Critical Review of Fair Machine Learning. arXiv:1808.00023, arXiv, \ arXiv.org, https://doi.org/10.48550/arXiv.1808.00023.
Gershgorn, Dave. (2018). “Facebook Says It Has a Tool to Detect Bias in Its Artificial Intelligence.” Quartz, 3 May , https://qz.com/1268520/facebook-says-it-has-a-tool-to-detect-bias-in-its-artificial-intelligence.
Google. What Is ML-Fairness-Gym? (2019). Google, 1 Apr. 2023. GitHub, https://github.com/google/ml-fairness-gym.
Graham, S. Scott. (2015). The Politics of Pain Medicine: A Rhetorical-Ontological Inquiry. University of Chicago Press. University of Chicago Press, https://press.uchicago.edu/ucp/books/book/chicago/P/bo20698040.html.
Hao, Karen. (2021). “AI Could Make Health Care Fairer—by Helping Us Believe What Patients Say.” MIT Technology Review, 22 Jan., https://www.technologyreview.com/2021/01/22/1016577/ai-fairer-healthcare-patient-outcomes/.
Hoffman, Kelly M., et al. (2016). “Racial Bias in Pain Assessment and Treatment Recommendations, and False Beliefs about Biological Differences between Blacks and Whites.” Proceedings of the National Academy of Sciences, vol. 113, no. 16, Apr. pp. 4296–301. Pnas.org (Atypon), https://doi.org/10.1073/pnas.1516047113.
IBM. AI Fairness 360. https://aif360.mybluemix.net/. Accessed 2 Apr. 2023.
Noble, Safiya Umoja. (2018). “Algorithms of Oppression.” Algorithms of Oppression, New York University Press.
O’neil, Cathy. (2017). Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. Crown.
Pierson, Emma, et al. (2021). “An Algorithmic Approach to Reducing Unexplained Pain Disparities in Underserved Populations.” Nature Medicine, vol. 27, no. 1, 1, Jan., pp. 136–40. www.nature.com, https://doi.org/10.1038/s41591-020-01192-7.
Poslusny, Catherine. (2018). “How Much Should Your PET Scan Cost?” New Choice Health Blog, 31 July, https://www.newchoicehealth.com/pet-scan/cost.
Sabin, Janice A. (2020). “How We Fail Black Patients in Pain.” AAMC, 6 Jan., https://www.aamc.org/news-insights/how-we-fail-black-patients-pain.
Staton, Lisa J., et al. (2007). “When Race Matters: Disagreement in Pain Perception between Patients and Their Physicians in Primary Care.” Journal of the National Medical Association, vol. 99, no. 5, May 2007, pp. 532–38.
S. Scott Graham (May 2023). “The Dangers of Ethical AI in Healthcare.” Interfaces: Essays and Reviews on Computing and Culture Vol. 4, Charles Babbage Institute, University of Minnesota, 32-39.
About the author: S. Scott Graham, PhD, is Associate Professor in the Department of Rhetoric and Writing at the University of Texas at Austin. He has written extensively about communication in health science and policy. He is the author of The Politics of Pain Medicine (University of Chicago Press, 2015) and The Doctor and The Algorithm (Oxford University Press, 2022). His research has been reported on in The New York Times, US News & World Report, Science, Health Day, AI in Health Care, and Scientific Inquirer.
Utah is an unparalleled exemplar of how creating a global center of excellence in an emerging specialty of computer science and engineering is possible with government seed funding. It was a special moment when the Advanced Research Projects Agency’s Information Processing Techniques Office (ARPA, IPTO) awarded the University of Utah $5 million ($43 million in today’s dollars) over six years, 1966 to 1972, for a project entitled “Graphical Man-Machine Communication” to launch the field of computer graphics and create a leading center for research and education. Three years earlier IPTO funded “Mathematics and Computation,” or Project MAC at MIT, also for six years, 1963 to 1969 (initially $2 million/year, but this grew to over $3 million/year). Given MIT’s Whirlwind (a real-time precursor to SAGE) in 1951, launching Lincoln Lab in that same year, and MIT spinoff nonprofit MITRE Corporation, in Bedford, Massachusetts, in 1958, past, major Department of Defense support had helped make MIT a top computing center prior. As such, Project Mac extended core areas of research and made an excellent computer science program far stronger. What was impressive about Utah was IPTO provided a half dozen years of support, far less than half the funds that IPTO awarded to Project MAC, and extremely talented and creative people ran with it and created a center of excellence anew. The Kahlert School has embraced the words of one its most famed and early doctorates (1969), Turing Award winner Alan Kay, “The best way to predict the future is to invent it.”
Dave Evans, Ivan Sutherland, other faculty, and graduate students made it happen in Utah. It changed from a program to a department (1973) to a school (2000), and throughout, it has achieved amazing feats. What came through so strongly in hearing talks, panel discussions, and meeting and engaging in conversations with the pioneers over two days in Utah this March, is that the research and development extending from the University of Utah and its alumni, was and is a product of a quite special culture.

Through the great leadership of Kahlert School of Computing Director Mary Hall, and the tremendous faculty at the school, that core, special culture, with some newer elements and commitments added, thrives today. Utah is one of the leaders in computer science and remains unmatched in graphics within computer science. The Kahlert School of Computing also impacts the world with newer tracks, such as Data Science and Software Development, and possesses a strong commitment to diversity, equity, and inclusion. Joining Hall and Dean of Engineering Richard B. Brown in this commitment to excellence and inclusion, it was also a pleasure to meet Vice President of the Kahlert Foundation, Heather Kahlert. The foundation’s support to the school recently led to its naming to become the Kahlert School of Computing, and her family foundation has supported an important initiative on inclusivity within the school, entitled “Programming for All.” Also impactful, John and Marcia Price recently made a $50 million donation to the College of Engineering, and their lead gift made the new, $190 million, John and Marcia Price building possible. Opening soon, it will house the Kahlert School of Computing and allow for its rapid expansion of existing and new areas of computing education and research.

There actually were three events on 23-24 March 2023 held in unison—the full day 50th Anniversary of the Computer Science Department of the University of Utah; followed on the second day morning IEEE Milestone Dedication; and then the afternoon Graphics Symposium. The three were complementary, reinforcing and expanding on each other in highly constructive ways. Most of the time, the program focused on looking back, but importantly, it also looked forward. Contributing to both was a fantastic day one keynote by Telle Whitney, past, longtime CEO of the Anita Borg Institute. Whitney is also co-founder of the Grace Murray Hopper Celebration, as well as of the National Center for Women and Information Technology (NCWIT). Nobody has done more to advance women in computing than Telle Whitney and to carry on the early work of her fellow computer scientist and collaborator Anita Borg.
On day two, consultant and IEEE Milestone Coordinator Brian Berg awarded an IEEE Milestone to the University of Utah Kahlert School of Computing for the department/school’s pioneering work in graphics. Berg presented the award to the school’s Director, Mary Hall, and the Dean of Engineering, Richard B. Brown.
This prestigious IEEE Milestone Award is an elite designation in technology. In computing, developments such as Bletchley Park Code-breaking; the ENIAC; MIT’s Whirlwind Computer (real-time); Moore’s Law; UCLA, and the (ARPAnet)/Internet have been awarded IEEE Milestones (which includes a bronze plaque—on day two, a video of Hall and Brown’s unveiling of the Utah CS plaque was played). Outside of computing, IEEE Milestones include Samuel Morse and Alfred Vail’s “Demonstration of Practical Telegraphy” in 1838; “Thomas Alva Edison’s Menlo Park Laboratory” created in 1876; and “Reginald Fessenden Wireless Radio Broadcast” in 1906. In short, it is a major honor and a useful IEEE program commemorating and exploring the past. Brian Berg has added much to the IEEE Milestone program, for more than a dozen years leading many IEEE Milestone efforts in the history of computing, software, and networking for IEEE Region 6, the Western United States.

Hall organized and was Master of Ceremonies for the magnificent day one “50th Anniversary of Computer Science at the University of Utah” symposium. She kicked off the event with an informative historical overview, drawing on the David Evans Papers and other archival materials.
Odd Ducks and Grand Challenges
ARPA funding was a necessary but not in itself sufficient element to foster Utah leading the way with the computer graphics revolution. Even having two of the most brilliant pioneers in computer graphics—hiring David Evans in 1965 to start the CS program and attracting Ivan Sutherland away from Harvard to join Evans—was not enough. The final, and arguably the most important ingredient, was the environment and culture that Evans set starting with his arrival (leaving the faculty of Cal Berkeley) in the mid-1960s, and that Sutherland contributed to mightily as well with his arrival in 1968.
There were other standout faculty in the early years, including but not limited to William Viavant, who served from 1964 to 1987, and the late Elliott Organick, who contributed to operating systems research and education and related areas of computer science with his nineteen books—including one I have devoured again and again on Multics and its security design (security and privacy are two of my areas of historical and sociological research). Also contributing to first-day events were impactful faculty who joined the department in the 1980s and beyond. They added greatly to the event and showed the breadth of the department in so many areas of computer science—Al Davis, Duane Call, Chuck Seitz, and Rajeev Balasubramonian. Program alum, Kahlert School Research Professor, and Flux Research Team Co-Director Robert Ricci’s moderation of a panel with graduates David Andersen of Carnegie Mellon and Cody Cutler from Amazon was especially intriguing in exploring “…Network Research, from ARPANET to Emulab and Beyond.”
Alan Kay is among the first and most famed of Utah CS doctoral alums (1969). His quote on inventing the future is fitting given he helped build the office of the future at Xerox PARC in the 1970s. Kay provided leadership in creating windows-oriented graphical user interfaces (GUI) and made major contributions to object-oriented programming (OOP), including his pivotal leadership creating the OOP-optimized Smalltalk language with Adele Goldberg, Dan Ingalls, and others. Kay’s presentation was by video, and focused on Dave Evans, Ivan Sutherland, and the environment of CS at Utah in the 1960s. Another, early and long-famed graduate, Jim Clark, also invented the future in founding Silicon Graphics and later Netscape. He, too, gave a brief and inspired talk on day one—his was in person.
As a social and organizational historian of computing, Utah has long fascinated me, and I have enjoyed the oral histories that have been conducted by past and current colleagues of the organization I am now privileged to direct, The Charles Babbage Institute for Computing, Information, and Culture. Perusing our unparalleled archives on computer graphics (many collections), and reading and re-reading the secondary literature has been a joy—including and especially past CBI Tomash Fellow Jacob Gaboury’s stellar, award-winning new book, Image Objects: An Archeology of Computer Graphics, and long ago, Founding CBI Director Arthur Norberg and Judy O’Neill’s classic Transforming Computer Technology: Information Processing for the Pentagon, 1962-1986.
How does an ARPA grant and two extremely gifted scientists create an unparalleled global center of excellence at a state school with a smaller state population (about 30th)? How does it succeed in fostering such an organizational culture to attract and cultivate the people to succeed on such a grand scale? Beyond Evan and Sutherland’s leadership gifts, high standards, and generosity, I would argue that not being surrounded by an overall, existing elite (Ivy or equivalent like MIT or Stanford) institution was a major plus. It helped facilitate the freedom for the faculty and students to experiment, to take risks, and to think big. That was my belief before traveling to Utah for the two days of events, and it was reinforced by the program, reminiscences, and discussions there.
Evans and Sutherland’s entrepreneurial drive shaped the department and pioneering graphics company Evans and Sutherland, but it was not the Silicon Valley style entrepreneurism of moving fast and breaking things. Instead, it was tending to the necessary money and resources side of the equation, and focusing on the nurturing and creative sides, more akin to a metaphor raised at the event several times, to “cultivating a garden.” This was a garden that encouraged talented graduate students, faculty, and company team members to grow the next new thing, the code, the tools, and the devices that could have a positive impact on science, knowledge, work, and leisure. Over the two days of meetings, the importance of the physical setting came through as a meaningful factor as well, the mountains and their tremendous beauty, the skiing, the retreats, and the frequent computer science meetings held at the picturesque Alta Lodge.
In starting a new program and seeking a certain culture that was different from other emerging schools in computer science, Evans looked for outliers in the graduate students he (and colleagues) admitted to the program. The seeking of “odd ducks,” was foundational and essential to the intellectual freethinking, and creative culture that he cultivated with the program from his formation of it in 1965 (the Computer Center launched in 1958 and grew to a staff of 30 people), one of 11 such programs at the time.
In 1968, with Ivan Sutherland’s arrival, resigning from his Associate Professorship in Computer Science at Harvard to become a Professor of Computer Science at Utah, and the ARPA IPTO funds, the program really took off. He and Evans were the two top researchers in the new field of graphics—they essentially invented it. Sutherland especially so, with his path-breaking 1963 dissertation on Sketchpad. Sketchpad was a legendary computer graphics program that transformed computer science. It influenced so much—from Human-Computer Interaction (HCI), Computer-Aided Design (CAD), object-oriented programming to GUIs, and virtual reality (VR). He had the additional insight to do a film demo that conveyed to the emerging field of computer science that a new major domain within it, graphics, was possible.
As Sutherland reflected during a panel at the event, ARPA IPTO Director J.C.R. Licklider had convened a group of top scientists and military leaders to see Sketchpad and meet with him. Despite his young age Sutherland was essentially a legend shortly after his dissertation. In 1964, Sutherland, only twenty-six years old, followed Founding Director Licklider in taking the reins to become the second ARPA IPTO Director, funding basic research largely at universities that helped transform the new field of computer science in areas such as time-sharing, AI, and other early graphics and networking work. Two of the most important grants in IPTO’s history were Project Mac (by Licklider in 1963) to MIT in artificial intelligence and time-sharing (Multics) and the six-year grant (by Robert Taylor in 1966) to the University of Utah in graphics. Other critical 1960s IPTO grants provided the basis of the ARPAnet. Utah has the distinction of being one of the four nodes of the ARPAnet at its launch as a four-node network in 1969.
Given Evans’ and Sutherland’s immediate respect for each other, their visionary, and entrepreneurial personalities, they became immediate friends and collaborators. And coming together at Utah was also about starting a company. Sutherland reminisced with a smile, whether Evans was to join him in Cambridge, or he was to go to Utah came down to “he [Evans] had seven kids and I just two.” It was fortuitous for both scholars, for the field of graphics, for the U, as Utah is affectionately known. It was also beneficial to the company, Evans and Sutherland. The University of Utah likely had greater opportunity for freedom than Sutherland’s Harvard, Cambridge, or Boston might have had for the company. Evans and Sutherland cultivated an overlapping family-type environment in both settings and endeavors. For the company, this made it all the easier to retain its talented computer scientists over the long term—good people tend to job-hop more in Silicon Valley and in Boston/Cambridge.
Evans and Sutherland, trailblazing graphics commercially, increasingly brought the technology to the world in a fast-growing range of applications. They attracted a top venture capital firm in Hambrecht and Quist, and their company was soon valued at $50 million. In just ten years, it grew from $10 million in revenue to $100 million in revenue.
As Sutherland conveyed about himself and Evans, and many others at the recent symposia reinforced, at the University of Utah Computer Science Department and at Evans and Sutherland, the two leaders sought to have as flat organizations as possible. Also important to them was assuring the satisfaction of everyone contributing to something larger than themselves. Seeking and solving hard problems was key to the student and employee/researcher’s satisfaction. The challenges could add to a sense of common purpose and a closeness of individuals and feeling part of the team. The graduate students became part of Evans’ and Sutherland’s extended family and they frequently had them to their homes to socialize.

Early Graphics
The many images shown at the event exemplified the words of the largely retired set of standout graduates who spoke and participated in its panels. This included showing a costume party photograph of playful attire and big smiles on the faces of faculty and graduate students in the Evans’ home. Regarding the company, Evans and Sutherland, there is one data point that goes beyond just the speakers and hints at the broader experience of employees being very positive and a family-like atmosphere, it is the retirement group and its continuing so many years. This sizeable group has a picnic reunion each year, the large numbers of people coming to this event year after year is suggestive of the positive culture of the company over decades.
Is there a potential risk of exaggeration or embellishment of the culture given the people speaking at the event had impressive careers and legendary accomplishments—a selection bias? Certainly, and further research into this culture through oral history, the David Evans Papers, and other archives likely would be fruitful and fascinating. For now, it seemed to me the group was large enough, and the message clear enough from people speaking, often quite emotionally, and always in a way uniquely their own, to get a telling sense of this culture and environment that Sutherland and Evans, the people, and Evans and Sutherland the company, created.
The participants in the event (especially the second day symposium specifically on graphics) were primarily graduate students from the late 1960s and the 1970s (though not exclusively). In the images and the talks there were tremendous accomplishments of alumni from multiple continents. Nonetheless, most were white and male. This was not unique to Utah. Diversity of gender participation and inclusion were challenges across computer science prior to a mid-1980s peak in women majors (reaching 38 percent), as well as from the early 1990s forward to today. Women’s participation as CS majors has generally been in the teens to low twenties, and at times the lower teens, apart from the mid to late 1980s. As such, Telle Whitney’s wonderful talk on gender, both historical and prescriptive, and highlighting some incredible women, added so much to the event.
For the remainder of this essay reflection, I will discuss several keynotes and other talks that especially resonated for me regarding University of Utah Computer Science Department/School of Computing culture and carrying of this culture impactfully into the broader world by faculty and alumni. In selecting a handful to discuss, I want to stress that all of the panel discussions and talks were compelling and fascinating, and many I do not highlight in what follows also exemplified the special culture of CS and The Kahlert School of Computing at the University of Utah.
Impacting the World at Scale: Nvidia, GPUs, and LLMs
Steve Parker gave a compelling keynote address on “Utah and the Frontiers of Computing.” Like a number of doctorates of the program, he later was a professor within it. For the past sixteen years he has been at Nvidia, and he currently serves as Vice President, Professional Graphics at the corporation, which has strategically led in skating to (and inventing and shaping) where the puck is going, rather than where it has been (such as Intel did in stumbling fashion), in microcircuitry—leading the way with Graphical Processing Units. GPUs are central to gaming, an area Nvidia has long served, and the far larger opportunity is that they are now also concentrating on large language models, machine learning, and many application areas. As OpenAI, Microsoft, and Google are seeking to exploit the opportunity for general markets and consumers (in my mind with too little HCI and user experience research and testing of how ChatGPT and Bard might amplify societal biases and extend inequalities, as search has done), Nvidia is focused on enterprise and targeting verticals.
In addition to some wonderful graphics displays Parker and his team did for the presentation, he refreshingly acknowledged the ethical critique with "search" and the importance of research and ethics in getting things right to have a positive impact on the world with large language models, with applications of generative artificial intelligence. A theme throughout was how researchers and leaders at corporations such as himself are “standing on the shoulders of giants” in Evans, Sutherland, and others. This is very much true in both the technical sense and organizational and decision-making sense with stewardship of machine learning out in the world. Parker concluded on a humorous note, with a slide of song lyrics after he asked ChatGPT to “Write a rap song on the history of computer graphics at the University of Utah.” To give a brief sense…. Verse 2 (1980s) … “In the eighties, Pixar joined the crew; and they worked on RenderMan, which was something new. It made computer graphics look oh so fine; And it’s still used today, it stood the test of time…”
Gender, Inclusion, and Innovations of Extraordinary Women
While ethics was a portion of Parker’s talk, it was the focus Telle Whitney’s excellent keynote address which preceded it on day one. Whitney was an undergraduate at the University of Utah and went through several potential majors before settling on Computer Science (BS 1978). These included Theater, Political Science, and English. She took an Interest Inventory Test and scored exceedingly high in programming. An advocate for her was Professor Richard F. Riesenfeld. Whitney earned her Ph.D. from Caltech in Computer Science working under the legendary Carver Mead, the co-inventor of Very Large-Scale Integration (VLSI), with Xerox PARC’s Lynn Conway. Doctorate in hand, by the mid-1980s she went on to technical and managerial positions at semiconductor companies Actel and Malleable Technologies. She also held senior leadership roles at a few tech startups. With her friend, Anita Borg, she was co-founder of Institute for Women and Technology, which Borg ran until she became terminally ill with brain cancer. In 2002 Whitney, initially temporarily, took over to lead the institute as CEO, which was renamed as the Anita Borg Institute, and later AnitaB.org. She ended up staying and was the CEO and President until she retired from role in 2017. In 1994, Borg and Whitney launched the Grace Hopper Celebration, which that year was a gathering of 500 women, an event for research, socializing (including dance parties), recruiting, and professional support. It has continued to grow steadily and is tremendously impactful to those who attend and to advancing women’s access and opportunities in computer science. There is a long way to go, but AnitaB.org, the Grace Hopper Celebration, and NCWIT are powerful and positive forces.

{kind=link}
Whitney spoke about the Anita Borg Institute and its co-founding of the Grace Hopper Celebration that started strong and has only grown since. Participation rates of women in computer science remains a challenge. In the biological sciences there is near gender parity (around 50 percent) women. In computer science, in recent years, numbers have been around 20 percent women at the bachelor’s and at the Doctoral degree levels, while a bit higher for Master’s, but still under one-third. Women’s participation in computer science even lags that of engineering overall. The early part of Whitney’s address was on underrepresentation of women historically and today and the very important point that it is both an inequity and to the detriment of computer science, losing out on so much talent and creativity.
The last two-thirds of Whitney’s talk was profiling five women and what they are doing in leadership, advocacy, and as role models to advance issues of equity and inclusion for women in computer science. Whitney offered rich cases of all five, I provide brief mention below.
- Cecilia Rodriguez Aragon—Professor of Human Centered Design and Engineering at the University of Washington, who co-invented treap data structure.
- Ashley Mae Conard—Computational biologist who works as a Senior Research at Microsoft Research.
- Aicha Evans—Computer engineer who served as Intel’s Chief Strategy Officer. In 2019 she became CEO of Zoox, a self-driving technology firm, and remains CEO of the Division after Amazon acquired Zoox for $1.3 billion.
- Mary Lou Jepsen—CEO of Openwater and co-founder of One Laptop per Child.
- Fei Fei Li—Professor of Computer Science at Stanford who in 2017 started AI4All and Co-Director of the Stanford Institute for Human-Centered Artificial Intelligence.
Whitney began studying CS at Utah, became a standout computer scientist and entrepreneur in industry, and has been an unparalleled leader for women in technology in leading AnitaB.org for fifteen years. Her message is important for all higher education institutions, one insightfully and inspirationally conveyed through biographical cases of these five tremendously accomplished and impactful women.
Utah and Influencing Corporate Cultures—Evans and Sutherland and Far Beyond
Dave Evans and Ivan Sutherland, by all accounts of the people on the program and in the audience, created an atypical corporate culture at their company that was analogous to how they built the University of Utah’s program/department into a center of excellence. This included seeking driven individuals who were creative and interested in tackling and solving big problems. It also included a non-hierarchical management structure with few layers. This was evident in Robert Schumaker’s insightful and engaging presentation. He joined General Electric (GE) in 1960 working on visual simulation systems but ran into dead ends in trying to get customers to contract for his and Rodney Rougelot’s work on flight simulators. Without the contractors signing on, GE was not supportive of continuing the work. The two were recruited away by Evans and Sutherland in 1972 and had the freedom and the runway to succeed, and they did mightily for the company. While photos of basic one-story buildings and trailers Schumaker showed of Evans and Sutherland's "campus" may not have been impressive or inviting compared to GE, the environment and support was. Schumaker and Rougelot led work that resulted in selling 1,000 flight simulators to various airlines globally a mere year after joining the more conducive team atmosphere of Evans and Sutherland. Schumaker became Simulation Division President and after two dozen years with the company, Rougelot rose to become President and CEO of Evans and Sutherland in 1994.
The culture that Evans and Sutherland built (at the university and the company) shaped how founders and leaders managed at some of the most influential graphics and software companies in the world. This included at Pixar Animation Studios and Adobe.
Ed Catmull gave one of the most moving talks of the event. It began with his account of his graduate student days. In the doctoral program in its early years, he had classes with Jim Clark, Alan Kay, and John Warnock. Catmull made major advances in computer graphics contour and textual mapping. He went on to do pioneering work in film graphics but ran into difficulty selling the ideas and his early work, that is until Lucasfilm hired him in 1979 and he became Vice President of the Computer Division of Lucasfilm. In 1986 Steve Jobs acquired this division of Lucasfilm, which became Pixar.
Catmull is a co-founder of Pixar Animation Studios and worked very closely with Jobs. He was emotional in emphasizing writers have the early Steve Jobs, in his first stint at Apple Computer, pegged appropriately (his impatient difficult personality and disrespect of others) but fail to recognize that the experience of being pushed out of Apple changed Jobs. He expressed how the Jobs he worked with in leading Pixar was a changed man (it is not uncommon for journalists writing history to prioritize the story they want to tell, a sort of truthiness over truth). At Pixar, both prior to and after it was taken over by Disney in 2006, there was a culture of commitment to completing projects and taking the time and putting in the resources to do them right. Catmull articulated how Pixar and Disney had parallel functional departments and units, sometimes benefiting from each other, but had their own culture and identity. This was key to success, and it runs counter to ideas in management with M&A, of integration and eliminating overlap and laying people off to capitalize on efficiency. Catmull stated another key lesson (one taken from Utah) is participation in decision-making and processes and keeping powerful people out of the room or reducing the number of them in the room. These were keys to Pixar’s success with Toy Story (with the Utah Teacup a part of it of course); Toy Story II, III, and IV; Finding Nemo; Ratatouille; and its many other creative achievements and blockbuster hits.
Sutherland Still Future-Focused in His Stellar Presentation
At various times Ivan Sutherland took the stage on panels, and offered remembrances, interesting anecdotes, perspectives, and historical details. It was his end of the day one keynote that stood out for me. He gave a technical and overview talk on Single Flux Quantum as a wholly new path for the greatest challenges in computing today.
As Sutherland related, the challenges today to extend Moore’s Law, inability to continue to add/double components on a chip, or it drastically decelerating, amounts to hitting a “power wall.” This is what is limiting computing’s future as he sees it. Sutherland gave a powerful and compelling talk advocating for Single Flux Quantum as a path to pursue to address this challenge. It is distinct from both the Moore’s Law methods and paradigm as well as from quantum computing. The latter may be a few decades out still and will work for some scientific and engineering purposes, but far from all or even most applications in computing. In Single Flux Quantum, magnetic flux is quantized. Sutherland stated the worst part of semiconductors today are the wires. Single Flux Quantum does not have this problem, further it is fast, digital, and Turing complete. It has some challenges and Sutherland went through each, arguing the payoff could be tremendous and if the US does not do it other nations will.

To do Single Flux Quantum right, Sutherland advocated for government funding for 1,000 engineers to work on it. He emphasized Utah should be a part of this. In his twenties, in the 1960s, with Sketchpad and Head Mounted Display, Sutherland invented computer graphics, VR, Object-Oriented Programming, and more. Also, in his twenties (mid-twenties at that) he led ARPA’s IPTO in skillfully funneling funds to worthy projects that would change computing. At Utah he and David Evans, and their company, were soon beneficiaries of their own IPTO funding, and they did change the world. The impact of their students and former employees is profound and continues. I, like 99 percent plus of the population, do not have the technical understanding to assess Single Flux Quantum , but the case Sutherland made for it seemed deeply researched and informed. More importantly, some of the fraction of one percent who understand it were in the room. The questions after it, from top engineers, were also strong and some quite challenging. Sutherland handled them masterfully. At age 84 Sutherland is doing what he has always done, and it is line with a famed quote of one of his early star students Alan Kay, “the best way to predict the future is to invent it.” While Sutherland, by his own acknowledgement, will not likely lead the effort to conclusion given his age, he is seeking to be a policy advocate for it in a highly informed way and doing this in his typical virtuoso fashion. It was moving and resulted in an extended standing ovation from all.
Bibliography
[Most of this reflection/review essay is drawn from the presentations at the three events described over the two days put on by the Kahlert School of Computing at the University of Utah, 23-24 March 2023. Below are some books, articles, oral histories, and archives collections that have influenced my thinking on the history of computer graphics.]
Alias Wavefront Records. Charles Babbage Institute for Computing, Information and Culture Archives. University of Minnesota.
“COE Receives Major Gift.” (2023). COE Receives Major Gift, New Name - The John and Marcia Price College of Engineering at the University of Utah (January 11, 2023).
Gaboury, Jacob. (2021). Image Objects: An Archeology of Computer Graphics. (MIT Press).
Machover, Carl Papers. Charles Babbage Institute for Computing, Information and Culture Archives. University of Minnesota.
Misa, Thomas J. (2010). Gender Codes: Why Women Are Leaving Computing. (Wiley-IEEE Press, 2010).
Norberg, Arthur L. and Judy O’Neill. Transforming Computer Technology: Information Processing for the Pentagon, 1962-1986. (Johns Hopkins University Press, 1996).
Smith, Alvy Ray. (2010). A Biography of the Pixel. (MIT Press).
SIGGRAPH Conference Papers. Charles Babbage Institute for Computing, Information and Culture Archives. University of Minnesota.
Sutherland, Ivan Oral History, conducted by William Aspray, 1 May 1989, Pittsburgh, Pennsylvania. Charles Babbage Institute, University of Minnesota. Oral History Interview with Ivan Sutherland (umn.edu)
Jeffrey R. Yost (April 2023). “From a Teapot to Toy Story, and Beyond: A Reflection on Utah, Computer Science, and Culture.” Interfaces: Essays and Reviews on Computing and Culture Vol. 4, Charles Babbage Institute, University of Minnesota, 19-31.
About the author: Jeffrey R. Yost is CBI Director and HSTM Research Professor. He is Co-Editor of Studies in Computing and Culture book series with Johns Hopkins U. Press, is PI of the new CBI NSF grant "Mining a Usable Past: Perspectives," Paradoxes and Possibilities in Security and Privacy. He is author of Making IT Work: A History of the Computer Services Industry (MIT Press), as well as seven other books, dozens of articles, and has led or co-led ten sponsored projects, for NSF, Sloan, DOE, ACM, IBM etc., and conducted/published hundreds of oral histories. He serves on committees for NAE, ACM, and on two journal editorial boards.
In 1965 Gordon Moore observed how semiconductors evolved over time in both how they increased their capacity to hold and process data and how their costs declined in an almost predictable manner. Known as Moore’s Law, over time it proved remarkably accurate. This essay suggests that his observation could lead to a clearer definition of a Moore’s Law type of consumer behavior. Unlike in Moore’s case, where its proponent had observed close-up the evolution of computer chips and one could use his insight to generalize, we have less empirical evidence with which to base a precise description for how a consumer behaves.
Hence, doing the same with respect to consumers is more difficult. That is our reality. I hypothesize that consumers of digital technologies behaved as if they were knowingly applying Moore’s Law to their acquisition, use, and replacement of digital goods and services. The paucity of evidence about their behavior is evidence that we do not know how much one can generalize the way Moore did. One’s own experience with computing devices suggests the notion has possibilities.
People, living in the nation where this law first became evident in continuous innovations of microprocessors, became some of the earliest users of consumer digital electronics, from watches in the 1970s to PCs in the 1980s, the Internet and flip phones in the 1990s, to smartphones and digital home assistants in the 2000s. As use of digital products increases, the need to understand how consumers decided to embrace such technologies becomes urgent beyond business circles to include academic study of the role of information in modern society.
This essay suggests that at least one lesson about digital innovations understood by historians may be useful in assisting business leaders, economists, public officials, and other historians to understand why individuals became extensive users of digital products. It draws from Moore’s Law as a rough gauge of how hardware performance and costs evolved applied to users’ experiences.
This essay discusses how scholars could study consumer behavior. It is a call for users of all manner of computing-based technologies to be studied by testing the hypothesis that consumers may have behaved in a Moore’s Law sort of way. Because computing historians are already familiar with the role of Moore’s Law on the supply side of the equation, they should be able to use that tacit insight to begin understanding the demand side of the story.

Photo credit: IntelFreePress, https://www.flickr.com/photos/intelfreepress/8575080587/sizes/o/in/photostream/
The Historian’s Problem
Historians face the problem of understanding how and why people adopted so many digital consumer products in essentially one long generation. Digital consumer products account for over 50 percent of all IT sales in the world, the other half are traditional company-to-company sales. Sales are annually in the trillions of dollars and continue to increase at rates faster than do national economies. Sales of consumer electronics increased between 4 and 7 percent annually over the past several decades, as less “advanced” economies expanded their consumption of such devices too, notably, in recent years, in China and India. This constitutes an annual market of $1.7 trillion, not including costs of using Internet services, just devices and software. So, studying early adoption of PCs by students, or writing on the history of computing companies of the 1950s-1980s, is insufficient.
In one sense, this is an old conversation about the diffusion of technology. Economists and historians feel they understand the issue, because they rely on neo-classic economic theory to explain what is happening by studying how people pick what to appropriate based on their best interests. In such thinking, neo-classical economics is based on the assumption that people know about a particular technology and use such knowledge in their purchasing decisions. Consumers exhibit rational behavior. Such thinking also acknowledges that people pay a price for acquiring whatever information they have with which to make a decision. That sense of full rationality is being questioned by behavioral economic thinking. In 2017 economist Richard H. Thaler was awarded the Nobel Prize in Economics for demonstrating that people can act irrationally too, also that this behavior can be predicted. His work encouraged economists to identify how consumers behaved that way. If the underlying idea of Moore’s Law reflects consumer behavior, then economists and historians have a way of viewing how users of digital technologies approached them.
Between the 1960s and the end of the 1980s, business historians and others who focused on the evolution and adoption of technologies proffered an alternative explanation, called path dependency, to explain that current decisions were—are—strongly influenced by prior decisions. This prism made sense for decades, as scholars in multiple disciplines grappled with this latest general-purpose technology called computing. The problem is that none of these types of explanations are substantive enough to lead to more robust insights as to why and how individuals embraced IT so quickly, given that most consumers did not have sufficient technical insights that neo-classical economic thinking assumes. Path dependency, or perhaps lock-in, inches closer in assisting, but only in explaining why one device might seem more attractive than another once they are already familiar with a particular type of equipment, software, or process. If one were replacing their Apple smartphone with another Apple smartphone, path dependence explanations are helpful. But such thinking does not explain why that same individual acquired an Apple phone in the first place.
Historians have nibbled at the problem. Familiar examples include Ruth Schwartz Cowan, Trevor J. Pinch, Nelly Oudshoorn, and Frank Trocco, all who looked at how to study consumer behavior through a sociological lens. In 1987, Cowan recommended focusing on a “potential consumer of an artifact and imagining that consumer as a person embedded in a network of social relations that limits and controls the technological choices that she or he is capable of making.” Pinch and his collaborators advocated for case studies to identify relationships of technologies, relevant social groups, and consumption choices applying sociological methods. However, as Cowan observed, these scholars “have given us a prescription but precious few suggestions about how it may be filled.” So, the problem introduced in this paper has been with us for a long time yet to be resolved. Perhaps using Moore’s Law can provide a more prescriptive approach, furthering Cowan’s thinking and of social constructionist-oriented historians.
Table 1 is a list of some of the most widely adopted digital consumer products. While incomplete, it suggests the necessity to appreciate the diversity of devices, even before any conversation about myriad versions of each that appeared simultaneously and incrementally by thousands of vendors. IT experts avoided forecasting a slowdown in the evolution of general-purpose computing. As the sale of older technologies slowed, because so many people already had them (e.g., smartphones, laptops), new ones attracted them, such as intelligent home speakers, virtual reality products, and wearables.

Introductory Dates for Major Digital Consumer Products in the US* | Year |
|---|---|
| Microwave ovens | 1967 |
| Digital watches | 1972 |
| Handheld calculators | 1972 |
| Cellular telephones | 1973 |
| VCRs and videos | 1975 |
| Desktop computers (PCs) | 1975 |
| CD players | 1982 |
| Portable consumer telephones | 1983 |
| Betamax movie camera | 1983 |
| IBM PC and clones | 1981-1984 |
| Battery operated laptop computers | 1988 |
| Game consoles | 1980s |
| Digital home movie cameras | 1991 |
| Internet access | 1993-94 |
Digital cameras
| 1994 |
Flat TV screens
| 1997-99 |
| DVD players | 2003 |
| Blu-Ray players | 2006 |
| Smartphones | 2007 |
| Programmable home thermostats | 2008-2010 |
| Tablets | 2010 |
| Digital personal assistants | 2011 |
Smart (video) doorbells
| 2012 |
*Dates reflect when consumers at large were able to acquire these products.
How Economists Explain Demand for Consumer Electronics
Traditional economic thinking holds that consumer technologies are “public goods,” things widely available to anyone who desire them. To become available to “anyone,” requires that the consumer understand its value, has means to acquire, and is willing to pay for these. Most will not pay $5,000 for a Dell computer today but would for one at less than $500. Technological knowledge is also an important factor.
There is growing interest in the role of technical knowledge that makes these devices more accessible to consumers. Increasingly, people know that IT goods—hardware—are used with software to transform other goods, making them more valuable, such as computing to improve fuel efficiency in a car. Consumers see that as an advantage worth investing in for their car. In the 1980s, economists like Paul Romer added that injecting growing bodies of knowledge into goods made these of greater value. This is the idea of applying knowledge about a technology embedded in the actions of consumers, not just in the minds of those inventing new products. How else could one rationalize acquiring a PC in 1982 for $3,000 or an Apple phone in 2018 for $999? Economists argued that the abundance of knowledge created more value than scarcity. Debates around those issues continue, but as one observer explained, “It is the growth of knowledge that is the engine of economic growth,” and that means all manner of knowledge use, including what consumers thought. Economists explain that someone interested in acquiring a long-established product could find a great deal of information to inform their purchase decision, but less for new products just coming onto the market.
Consumers acquired IT products because they provided a utility or fulfilled a desire. PC users wanted to consume digital content (i.e., read the news, view a movie, or play a game), or to produce it, for instance word processing, or to send email. One question economic historians should want to explore is to what extent was that behavior attributable to general-purpose technologies evident with respect to digital tools and toys?
A new breed known as behavioral economists is examining the psychology of economic behavior. Some of these have concluded that, “economic value,” (i.e., price) still dominates purchase decisions trumping, but not eliminating, the power of emotional or social attractions. Experimentation with such phenomenon as the attraction of ring tones suggests people do not buy digital products just to improve their productivity, challenging older neo-classical economic beliefs. Often consumers acquired these for enjoyment, such as flat screens or online games, again value being consumption. Music, in particular, stimulated considerable demand for IT in the post 2000 period, while a decade earlier, video games. To appeal (entertain), social values of a particular technology and their playfulness had a role. Entertainment and social interactions provided the most significant motivator to acquire digital products.
Economists argue that consumers will not always have perfect knowledge of a digital product, so make mistakes, that is to say, do not always make the best choices to optimize their economic advantage. Consequently, consumers learn to avoid these. But, digital products are used so individualistically that users rely on personal experience to characterize benefits of a product (the idea that my use of an Apple PC is different than yours). The more effective they are in tailoring use of a digital product to their needs the more one can assume their attraction to it increases, even if the journey to that satisfaction is bumpy or long.
Knowledge of the product (genre of products and technologies) combined with experience with these is highly influential and normal. But like traditional economists predict, consumers learn what they want, balance needs and desires against costs, then act rationally. That line of reasoning remains economic orthodoxy and scholars in other disciplines have yet to see strong reason to challenge it. Historians seem more interested in how people value a digital product than economists who are more concerned with prices, each focuses on different issues.
Anthropologists began exploring the role of individuals in their acquisition of personal computing. Their earliest studies were based on consumer behavior of the 1980s and early 1990s. For example, in a study of the experience of English families acquiring PCs, they were treated as miniature institutions (e.g., like a company). They acquired the least expensive machines available, but then more frequently additional hardware and peripherals. Their acquisitions spilled over into other electronics with nearly half acquiring additional televisions and cassette players, some more tape players. As the study observed: “purchase of one or more home computers has also been stimulus to further purchase of more traditional brown goods.” Husbands had twice as much experience with PCs (presumably from job activities) as women and led the charge to acquire digital products. Once knowledge of a new class of products diffused into their homes, adaption escalated quickly. Neighbors and work colleagues had clearly talked to each other, at least among professional and managerial classes. So, points go to the economists because of affordability issues, while familiarity with the technology and its features shaped responses of households to these products. Influencing acquisition in both a Moore’s like fashion and path dependency, games played on television in the 1980s moved quickly to PCs.
What Marketing Experts Say About Consumer Behavior with Digital Products
Marketing professionals focus on how consumers react to such offerings. They have much to teach scholars in other disciplines. They want to predict how consumers will respond to new products and to persuade them to buy new ones. They argue that a consumer’s existing knowledge asserts major influences on their decision to acquire a digital product. The more knowledgeable a consumer is, the more likely they are to benefit from its use. Someone with knowledge of one technology is less likely to move to a novel one requiring new insights than a novice not wedded to an earlier digital device or software. If you are used to Microsoft Word on a Lenovo laptop, you are willing to accept new releases (editions) of either more readily than, say, to try a new word processing software operating within Apple’s operating system.
What can we learn about early adopters, individuals who appropriate a new digital product before the public at large? Marketing experts obsess over them because they are crucial to the success of a new product’s acceptance by consumers. Economists and historians pay insufficient attention to them. Early adopters often represent 10 percent of a new technology’s supporters and it is their successful use of a new product that encourages others to acquire these. “Influencers,” as they are called, tell relatives and friends how great (or terrible) a new product is and offer advice on how to deal with these. Peer influence plays an important role. College students are famous for being early adopters of smartphones, video games and tablets, and since they are physically near where marketing professors work, they represent a convenient, if not ideal, cohort for gaining insights. The more friends one had encouraging a specific purchase (or use), the more likely a student would adopt the device or new use (i.e. an app). Family influences play a statistically significant role in adoption decisions, too.
Just as semiconductor firms felt compelled to conform to Moore’s Law, so to consumers came to depend on and expect consumer goods manufacturers to introduce products that reflected productivity improvements expected of the semiconductor firms. These expectations suggest that consumers intertwined with that of semiconductor firms, creating a hidden interdependence between them and their suppliers, hence with marketing, because the latter had to document such behavior and then encourage it.
Role of Speed and Churn in Technology Options
General technologies emerged and diffused faster the closer one moved toward the present: a new automobile is today designed and produced in 24 to 36 months, as opposed to 48 months in the 1980s. It took over a half-century for telephones to be installed in over 50 percent of American homes, but only a decade for mobile phones. The list of examples is extensive. Older technologies took longer to diffuse to substantial levels, such as electricity, telephones, and radios, quicker for television. Rates of diffusion of digital products sped up in comparison. The number of innovations increased, as did both the speed with which they appeared and with which people acquired them. Our interest here is on the adoption rates of technologies.
Everett Rogers in his classic studies on the diffusion of innovations identified early adopters as crucial in explaining its uses and benefits to slower adopters who shared common interests. They tended to be younger, better educated, more affluent, informed, extrovert, and willing to take greater risks that their use of a new device would malfunction or fail exceeded what their neighbors or colleagues were prepared to embrace.
| Device | Years to 75% Adoption | Years to Estimated 25% Adoption |
|---|---|---|
| Microwave oven | 15 years (1967-1992) | unknown |
| Digital watch | unknown | 1970s |
| PC | 24 years (1978-2002) | 16 years |
| Portable phone | 25 years (1978-2003) | 13 years |
| VCR | 5 years (1988-19930 | 5 Years |
| Internet | 23 years (1993-2015) | 7 years |
| Digital camera | unknown (1986) | late-1990s |
| Smartphone | 10 years (2007-2017) | 3 years |
| Flat screens | unknown | unknown |
*Dates and percentages are estimates based on multiple chronologies and statistical data compiled using different data and calculating methods. Source: Census Bureau, US Department of Commerce.
Table 2 lists a sampling of digital devices and how long it took for 25 percent, then 75 percent, of the American public to acquire them. Implicit with these products was appropriation of the software necessary to operate them. The public took less time to acquire digital devices as they went through one decade after another. There is some debate about how to measure these rates of adoption, as the data in table 3 suggests. However incontrovertible is that the rate of acceptance sped up over decades worldwide, with only rates of diffusion differing from one nation to another.
| Device | Years to 50% Adoption by Home |
|---|---|
| PCs | 19 years |
| Cell phones | 14 years |
| VCRs | 12 years |
| CD players | 11 years |
| Internet access | 10 years |
| Digital TVs | 10 years |
| DVD players | 7 years |
| MP3 players | 6 years |
*Source: Adapted from US government sources by Adam Thierer, “On Measuring Technology Diffusion Rates,” Technology Liberation Front, May 28, 2009, https://techliberation.com/2009/05/28/on-measuring-technology-diffusion-rates/ (accessed July 2, 2012).
This trend is made more impressive because each category of products underwent significant technical and usability changes, causing users to learn new ways of doing things, an attribute of new products that normally should delay embracing a new generation of their devices. This happened, for example, when either Microsoft or Apple announced it would no longer support an earlier operating system, forcing users to change software, often also hardware. Smartphone manufacturers attempt to force the same behavior but have been most successful when adding functions, such as cameras.
To sum what is understood so far: Users worried about the complexity of a new device or service compared to their prior experiences. They were influenced by prior experiences, expectations, and relevance of specific goods to them. Peers, family, and reviewers influenced their views about a digital offering. They compared incremental changes of one device or software to another and how these fit into their path-dependent knowledge of a technology. Increasingly over time, they became concerned about the effects of an adoption on the privacy of their information.

A Proposed Explanation for When Individuals Embrace Technologies
My proposed explanation can be stated as a question because the hard evidence required to answer it in the affirmative is currently spotty, while the logic is attractive: Have users of digital technologies subconsciously learned to behave according to a variation of Moore’s Law?
Moore’s Law is partially enigmatic because it evolved over time. By the mid-1970s he was saying that changes in capacity and lowering of costs came every 18 months. That meant the cost of a transistor (its capacity) would decline at a predictable rate, helping to explain how computers became less expensive and smaller over time. Moore pointed out that his observation was not an expression of a phenomenon in physics or natural law, but rather, of an historical trend. That is an important distinction because his was a statement of how technologists could choose to behave; it was an expectation. Intel, which he ran, chose to develop new generations of semiconductors that doubled in capacity every 18 to 24 months for decades. Sufficient knowledge existed to implement such choices.
Can Moore’s observation be used to understand how people outside of a semiconductor factory responded to the innovations that came from within the computer industry? This question implies that regardless of the law’s future relevance, it asks if its prior manifestation is the right question useful to guide research about consumer behavior. One would expect that an engineer, computer scientist or vendor’s employee conscious of the law would integrate that insight into their personal behavior. That individual could be expected to delay by a year or two their acquisition of, say, a flat-screen confident that the $5,000 initial asking price would drop by some 20 percent compounded per year. But it is not clear that most people had such explicit insider knowledge of Moore’s Law, or even knew someone who did. Given the speed with which every new class of digital devices was appropriated by the public suggests that neither of these few “technically-in-the-know” few million individuals, including early adopters, were not enough to sway the behavior of hundreds of millions of users.
Let us restate the key hypothesis that should be studied: Consumers time their acquisitions consistent with the rate of innovations and pricing explained by Moore’s Law. It is as if consumers knew Moore’s Law and applied it to optimize when and what they acquired. Consumers know when to buy because of their prior experiences with digital devices, all of which reflected Moore’s Law at work. And how do we know that they have that prior experience? The well-documented sales data collected by vendors and governments preserve it, as do the three tables in this essay.
A corollary is that consumers subconsciously accepted that their behavior and use of digital devices transferred from one to another. Hand-held remote controllers, first acquired for TVs in the 1970s, are used today for turning on and off gas fireplaces, indoor lights, computational devices, and garage doors. Smartphones are routinely used as remote controllers for managing programmable devices in the home; key fobs to lock and unlock automobiles. Examples abound once one realizes that functions can be transferred from one device to another. Vendors encouraged that sense of universality. Apple conspicuously promoted integration of its products for decades, that is to say, their ability to communicate with one another, aiding lock-in to the Apple ecosystem. This ecosystem includes app store infrastructure, third-party platforms, and other cloud infrastructure—third-party social networking, of course, is economically viable because of the Moore’s Law trajectory and monetization of data in advertising. It also requires common user interfaces and ways of using devices from one to another. Apple sees that universality of function as a competitive advantage over Android devices. Consumers call for digital devices to communicate with their other digital goods, much as IT professionals demanded of IBM and its competitors for their workplaces since the 1960s.
Embedded in this corollary is sufficient confidence required to make acquisition decisions involving digital products, including new ones. Buying one’s first or second PC required significant research and courage, not just a great deal of money; far less so one’s first laptop. Then, or as a few years earlier (i.e., 1970s), moving from a desktop electronic calculator to a hand-held H-P digital calculator had the same effect. When the old H-P died, acquiring its replacement was hardly a conscious decision, it happened quickly. It helped that the consumer knew that before buying the replacement it would be far less expensive than the original H-P, unless H-P had added functions to newer models. People knew what any calculator could do and more-or-less how to use them. This same representative consumer took less time to decide to acquire a digital camera than their original 35-mm film one, and in the process enjoyed a bargain and far more functionality, even if the base camera cost the same as their original film camera. When flip phones first appeared, which consumers viewed as another advanced electronics product, with digital photography already part of their experience with other digital products, again the decision came quicker, and even faster with smartphones a half decade later, which included digital photography. Consumers became increasingly confident that they knew what they were doing, that risks of mistakes diminished in buying decisions, and that costs were manageable. In each instance, expectations were subconsciously set and met.
Underlying all this behavior was a growing body of experience, of tacit knowledge about digital consumer goods acquired over decades. A new generation of economists, psychologists, and marketing experts recognized the power of knowledge tied to social values and attractions in influencing decisions. While they still segmented users into such groups as experts, early adopters and laggards, users behaved essentially the same way. Acceptance had to “fit” prior experience and perceptions.
How Could Moore’s Law Be Leveraged Through Historical Perspective?
One can envision the hypothesis—research agenda—as a test to explore several issues. First, an attitude to embrace originates from taking the perspective of the consumer. Second, there have been so many consumer electronics introduced in the past half-century for which case studies are needed, almost on an item-by-item basis, such as about those in Table 1, to understand how each was acquired and used. Increasing our understanding of specific experiences with each test whether people were influenced by their prior experiences with others. That requires case studies.
As case studies are prepared, what kind of Moore’s Law-centric questions might one ask? Some of the most obvious include for each device or software the following:
- In what order did a consumer or group of consumers acquire new electronic devices and software? This is a question of chronology to establish the order of decision-making.
- Why was the new device acquired? Was it a new version or software release or an entirely new class of products (e.g., tablets, not a flip phone)? This gets to the issue of path dependency, because historians know that it occurs at the individual level, not just in corporate or governmental decision-making, yet we do not know if it crosses product lines.
- What role did prior experience with digital devices have on the decision to acquire a new, or different class of products? Following from Moore’s Law should chip manufacturers’ learning of how to improve on earlier components through experience also apply to consumers? The answer is not certain, but important to study further.
- What effect did a consumer’s interaction with other users (not just advertising, marketing, and good sales personnel) have on their acquisition and subsequent experience with their acquisition? The hypothesis here is that social or professional networking is a critical element, a deep bow to pioneering scholars Cowan, Pinch, and others.
- Does a user’s familiarity with a specific type of digital product lead that individual to choose a higher price device? Is that applied knowledge or simply comfort, or are the two ideas one and the same?
- What role does platform tribalism play? Is this like bikers reinforcing each other to always ride a specific brand of motorcycles? Is such conformance limited to specific cohorts and age groups, such as teenagers who are notoriously famous for being loyal to what is fashionable at the moment?
Outputs of such research can be framed in language familiar to those who study Moore’s Law. For one, measuring the time it takes to make an acquisition compared to when a device became available is a crucial source of evidence in support of the hypothesis that Moore’s Law behavior may be in play. Did the amount of time from when digital cameras became available in one national economy to when 25 or 50 percent of its population had one shorten as compared to the earlier acquisition of PCs? Did adoption of smartphones after digital cameras shorten even further, or not, as a result that prior experience with digital photography? If so, why? The assumption that the behavior is broad has to be tested, too. How fast should be measured and compared against how quickly smartphones with cameras were acquired?
Differentiate subclasses of users by individual needs and existence of specific digital goods. Early adopters behaved differently than naive consumers in each period. Active resistors did too. We do not know if initial appropriations are reflections of Moore’s Law behavior, or if more the case after a consumer has stepped onto the treadmill of a particular technology, which this essay suggests possibly reflects Moore’s Law once commenced and more certainly path dependency. My assumption is that a correlation exists, probably too, as a cause for the decline in film-based camera sales. But it has to be proven and reasons for that behavior verified. Another assumption that consumers understand they can port over specific functions from one class of products to another, confident in their ability to do so and to achieve the same results, needs validation.
Economists who looked at Moore’s Law are right to focus on relationships between innovations and costs to those who purchased the results. The same can be applied to consumer behavior. At a country level, but then at an industry level too, we need statistics cataloging the number of digital items acquired by consumers by year, device, then in comparative tables, so that one can do the necessary analysis to determine quantitatively rates of adoption. Similar data gathering followed by analysis of changing costs to consumers should be done to determine effects pricing had on rates of adoption. Built into the Moore’s Law hypothesis is the assumption that as goods dropped in price, more were sold and that after a while users came to expect a certain rate of price/performance changes to occur. Did that, in fact, happen? If not, the hypothesis weakens. If the correlation followed by validating consumer testimony is established, then the hypothesis is strengthened.
Economic Implications of a Consumer Moore’s Law
With so much spent on consumer digital electronics and other devices that share functional and economic characteristics, marketing, psychologists, and economists are studying how buyers and users behave. Do consumers, for example, approach acquisition and use of such technologies differently than non-digital goods? The answer is partially, but increasingly, yes, because they have to invest more time and energy to learn about a new device and how to use it, thus once understood are going to use that knowledge as criteria to judge future acquisitions. A vendor cannot introduce a product without training and considering its compatibility with prior devices and hope for the best. If they did not, people might be expected to continue to use 20-year-old releases of Microsoft Word or that ancient digital watch received as a Christmas present in 1975, rather than a smartwatch.
Second, products previously not thought as fitting under the umbrella of digital products are moving into that space. Tesla automobiles are seen as digital products manufactured by a Silicon Valley management team. What effect did the dearth of information have on consumer behavior, as was the case with information regarding health care options in the United States in the 1990s, or as the British recently experienced with Brexit? Already, consumers of medical services are trying to “play the odds” on when a cure, say, for their cancer will appear, hence shape their interim strategy for treating their condition. Home medical monitoring devices or wearables are rapidly coming onto the market, welcomed by these same consumers who earlier acquired smartphones, digital cameras, PCs, and the oldest, microwave ovens, VCRs and watches.
Third, consumers are learning about the nuances of using all manner of digitized products and services that affect their views. There is a body of studies about consumers transporting expectations from one industry to another, even to mundane activities with no apparent involvement of computing on their minds. It is easy to imagine them taking lessons learned in non-digital parts of their lives and applying them to digital products and conversely back to our concern, porting insights from one technology or knowledge base to another. Historians can increase our understanding of massive sets of activities involving billions of people.
A concern that the hypothesis makes obvious is If people anticipate and act upon price declines doesn’t Moore’s Law then reflect how it influences supply-side behavior? We do not know the answer with respect to consumers. If the answer is yes, that consumer behavior is more influential on the demand side, then is/was Moore’s Law less influential on users? What needs to be determined is whether consumers were just reacting to Moore’s Law for producers. Our hypothesis assumes the answer is not so clear; there is an agency at work on both sides of the supply/demand paradigm.
Implications for the History of Information Technology
Historians have studied the supply-side of consumer electronics more than about users of such devices and software. Yet, consumers massively outnumbered suppliers and employers. For example, Apple had 132,000 employees, but 588 million users of its products in 2016, more of both in subsequent years. Similar observations can be made about other digital products. As use of digital goods continues to seep into every corner of life and society, historians of most disciplines will encounter these and need to deal with their behaviors. This is a daunting task, because users of computing are fragmented cohorts. It is easier to write a history of IBM, for example, than about IBM’s customers; I know, because I tried. However, the concept of consumers acting as if applying Moore’s Law can be a helpful meme assisting scholars to deal with the effects of the digital.
Economist Kenneth J. Arrow was an early student of how asymmetric information affected behavior, arguing that sellers had more facts about a product than consumers. His insight stimulated decades of discussion about the role of information in economic activity, although the conversation had started in the 1950s. Further exploration of the notion of a consumer Moore’s Law might alter that information balance-of-power, tipping it more to the consumer, reinforcing another line of Arrow’s research that held there existed a general equilibrium in the market in which the amount of supply of something matched demand for it, more or less. He argued that consumer behavior involved “learning-by-doing,” which, as concept and observation, are compatible with the new psychological economics. His notion is also consistent with a Moore’s Law behavior by consumers, if we semantically modify it to “learning-by-using.” Enough research has been done on how consumers respond to digital products to confirm that learning becomes a core element affecting adoption of digital goods.
One could, of course, take the position that consumers are simply conforming to an old behavior that they replace technologies as new ones come along. That argument would only apply to a replacement, say, of an older release of Microsoft Word with a newer one, but not if a consumer in the 2000s added tablets and smartphones to their tool kit, or started using wearables. One could posit the null hypothesis that consumers respond to digital electronics the same way they do to other products. That requires no critique, because the reader knows that is not true; furniture, and pots are not the same as digital goods—these require little economic risk or investment of time when compared to electronics. Digital products operate with their own rates of innovation and production of new classes of goods and services, which is why we need to search for methods with which to understand them. That is why a lesson from the Moore’s Law experience might prove insightful.
Bibliography
Arrow, Kenneth J. (1984). Collected Papers of Kenneth J. Arrow, vol. 4, The Economics of Information, Belknap Press, Cambridge, Mass.
Brock, David (2006). Understanding Moore’s Law: Four Decades of Innovation, Chemical Heritage Foundation, Philadelphia, Penn.
Cowan, Ruth Schwarz (1997). A Social History of American Technology, Oxford University Press, New York.
Pinch, Trevor J. and Frank Trocco (2002). Analog Days: The Invention and Impact of the Moog Synthesizer, Harvard University Press, Cambridge, Mass.
Rogers, Everett M. (2005). Diffusion of Innovations, Free Press, New York.
Thaler, Richard H. (2016). Misbehaving: The Making of Behavioral Economics, W.W. Norton, New York.
James W. Cortada (March 2023). “Can Moore’s Law Teach Us How Users Decide When to Acquire Digital Devices?” Interfaces: Essays and Reviews on Computing and Culture Vol. 4, Charles Babbage Institute, University of Minnesota, 1-18.
About the author: James W. Cortada is a Senior Research Fellow at the Charles Babbage Institute, University of Minnesota—Twin Cities. He conducts research on the history of information and computing in business. He is the author of IBM: The Rise and Fall and Reinvention of a Global Icon (MIT Press, 2019). He is currently conducting research on the role of information ecosystems and infrastructures.