Robust and Generalized Perception Towards Mainstreaming Domestic Robots

Between 2015 and 2050, it is predicted that individuals over 60 will nearly double from 12% to 22%[1], along with rapidly growing healthcare needs[2]. To meet these healthcare demands, we have seen promising robotics applications, especially in taking over the repetitive chores of nurses and doctors[3]. Although these examples show potential ways for robots to assist people, they are limited in their capabilities. To be helpful in a home environment and provide personal care in the near future, these robots should become more capable of autonomously performing various tasks such as cooking, serving food, cleaning, doing laundry, etc. Currently, however, our robots cannot see the world as humans do, and perceiving unstructured environments remains challenging and largely unsolved. Therefore, there is a great need to advance the perceptual capabilities of robots to achieve the long-term goal of having a robot butler/nurse capable of assisting people.
To understand the perceptual demands of a general-purpose robot, let us consider an example task of making an omelet. Various categories of objects are involved in this single task (as shown in Figure 1); eggs, butter, salt, pepper, omelet (brittle, semi-solid items, granular substances), fridge, dishwasher, cabinet (articulated objects), pan, fork, bowl (rigid objects), counter, stove (place/object locations), and wipes or cloth (deformable objects). A robot must perceive and interact with these categories of objects to accomplish this seemingly simple task.
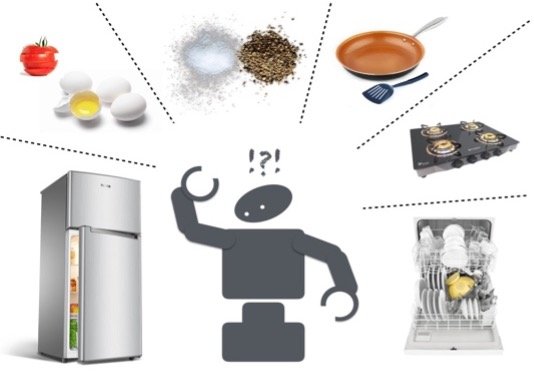
Like the above example, most tasks in our environment involve multiple object categories, and invariably generalization becomes essential. Moreover, each object category poses a unique set of challenges in perception to enable grasping and manipulation. On top of these challenges, occlusions make the perception problem even more complex and necessitate the accommodation of perceptual uncertainty. Common indoor environments typically pose two main problems: 1) inherent occlusions leading to unreliable observations of objects, and 2) the presence and involvement of a wide range of objects with varying physical and visual attributes (i.e., rigid, articulated, deformable, granular, transparent, etc., see Figure.1). Thus, we need algorithms that can accommodate perceptual uncertainty in the state estimation and generalize to a wide range of objects. Probabilistic inference methods have been highly suitable for modeling perceptual uncertainty, and data-driven approaches using deep learning techniques have shown promising advancements toward generalization. Perception for manipulation is a more intricate setting requiring the best from both worlds.
Accommodation of perceptual uncertainty in state estimation: Starting from a collection of rigid objects on a table to highly articulated objects with rigid body parts, such as cabinets, our research has contributed to various Generative Probabilistic Inference (GPI) techniques for state estimation [1, 2] The most impactful contribution in this line of work is “Pull Message Passing for Nonparametric Belief Propagation (PMPNBP)[1]” where the problem of indoor scene estimation is formulated as a Markov Random Field (MRF). PMPNBP caters to the high-dimensional and multimodal demands of cluttered indoor scenes while being computationally feasible. With the computational advantage of PMPNBP, we show the first demonstration of practically applying a belief propagation method for articulated object pose estimation, with full pose prediction for each object part.
Generalization to a wide range of objects: Real-world objects are too diverse, and assigning handcrafted explicit object representations such as 6DoF poses for robot manipulation tasks is neither scalable nor trivial. To generalize state estimation to a wide range of objects, we are actively investigating and developing data-driven methods to implicitly understand objects and their spatial composition [3, 4] while grounded in robotic manipulation tasks. We explore ways to learn object-centric representations from large amounts of simulated task execution data. “Spatial Object-centric Representation Network (SORNet)”[5], a preliminary work in this direction, showed promising generalization of learned object representations to unseen object instances. SORNet representation captures continuous spatial relationships while being trained purely on logical relationships.
Motivated by the above research and challenges in human environments, the Robotics: Perception and Manipulation (RPM) Lab led by Prof. Desingh focuses on addressing the fundamental question, “What should/does/can a physical object in our environment mean to a robot?” thus leading to the following research questions:
- How can a robot perceive and reason about objects in the human environment?
- How can a robot interact with these objects?
- How can a robot compose its interactive skills into performing meaningful tasks?
- How can a robot learn to do all the above toward seamless interaction and task execution?
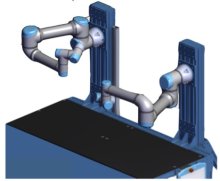

The RPM lab has a dual-arm manipulation setup and a mobile manipulator. The dual-arm manipulation setup is built with two UR5e robot arms from the Universal Robot company (Figure 2). This setup will be used for performing contact-rich manipulation tasks. The mobile manipulator is the Spot robot from Boston Dynamics (Figure 3). This robot will be used for perception and mobile manipulation research beyond laboratory settings.
References:
[1] Karthik Desingh, Shiyang Lu, Anthony Opipari, and Odest Chadwicke Jenkins. Efficient nonparametric belief propagation for pose estimation and manipulation of articulated objects. Science Robotics, 4(30), 2019.
[2] Zhiqiang Sui, Lingzhu Xiang, Odest C Jenkins, and Karthik Desingh. Goal-directed robot manipulation through axiomatic scene estimation. The International Journal of Robotics Research, 36(1):86–104, 2017.
[3] Aaron Walsman, Muru Zhang, Klemen Kotar, Karthik Desingh, Ali Farhadi, and Dieter Fox. Break and make: Interactive structural understanding using lego bricks. In European Conference on Computer Vision, 2022.
[4] Junha Roh, Karthik Desingh, Ali Farhadi, and Dieter Fox. LanguageRefer: Spatial-language model for 3d visual grounding. In 5th Annual Conference on Robot Learning, 2021.
[5] Wentao Yuan, Chris Paxton, Karthik Desingh, and Dieter Fox. SORNet: Spatial object-centric representations for sequential manipulation. In 5th Annual Conference on Robot Learning, 2021.