Data Science
Materials for sustainability
Biological engineering
Complex systems





Stabilizing a Double Gyroid Network Phase with 2 nm Feature Size by Blending of Lamellar and Cylindrical Forming Block Oligomers
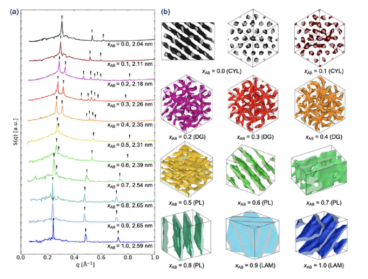
Molecular dynamics simulations are used to study binary blends of an AB-type diblock and an AB2-type miktoarm triblock amphiphiles (also known as high-χ block oligomers) consisting of sugar-based (A) and hydrocarbon (B) blocks. In their pure form, the AB diblock and AB2 triblock amphiphiles. Read the full article at the ACS Publications website.
Related Faculty:
Ilja Siepmann, Tim Lodge, Kevin Dorfman, Frank Bates, Mahesh Mahanthappa
Fingerprinting diverse nanoporous materials for optimal hydrogen storage conditions using meta-learning
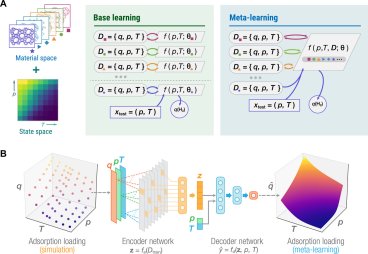
Adsorptive hydrogen storage is a desirable technology for fuel cell vehicles, and efficiently identifying the optimal storage temperature requires modeling hydrogen loading as a continuous function of pressure and temperature. Read the full article at Science's website.
Related Faculty:
Approach for statistical analysis of oxide- and sulfate-induced hot corrosion of advanced alloys
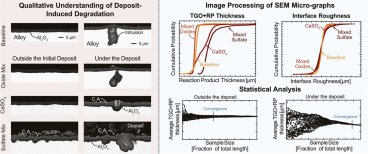
This work develops an automated image and statistical analysis protocol to characterize and compare the effect of three deposits on the accelerated non-uniform degradation of a model alloy (FeCrAlY) at 1025 °C in dry air. Read the full article at ScienceDriect's website.
Related Faculty:
New tolerance factor to predict the stability of perovskite oxides and halides
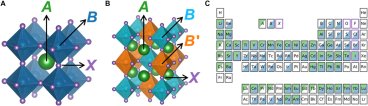
Predicting the stability of the perovskite structure remains a long-standing challenge for the discovery of new functional materials for many applications including photovoltaics and electrocatalysts. Read the full article at Science's website.
Related Faculty:
Combinatorial Polycation Synthesis and Causal Machine Learning Reveal Divergent Polymer Design Rules for Effective pDNA and Ribonucleoprotein Delivery
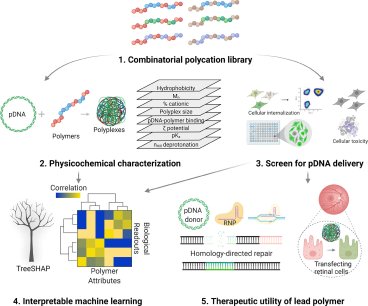
The development of polymers that can replace engineered viral vectors in clinical gene therapy has proven elusive despite the vast portfolios of multifunctional polymers generated by advances in polymer synthesis. Read the full article at the ACS Publications website.
Related Faculty:
Model-guided engineering of DNA sequences with predictable site-specific recombination rates
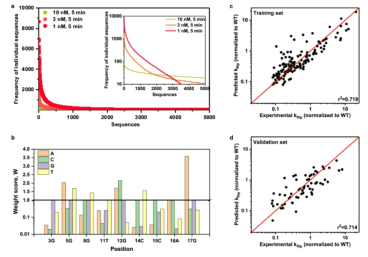
Site-specific recombination (SSR) is an important tool in synthetic biology, but its applications are limited by the inability to predictably tune SSR reaction rates. Facile rate manipulation could be achieved by modifying the DNA substrate sequence; however, this approach lacks rational design principles. Read the full publication at Nature Communication's website.
Related Faculty:
High-throughput developability assays enable library-scale identification of producible protein scaffold variants
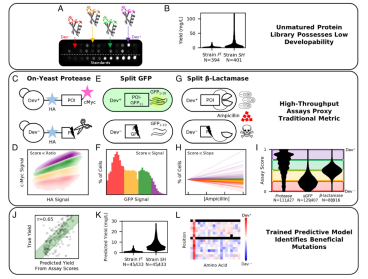
Poor protein developability is a critical hindrance to biologic discovery and engineering. Experimental capacity limits variant analysis. We demonstrate the ability of an on-yeast protease assay, a split green fluorescent protein assay, and a split β-lactamase assay to predict recombinant protein production yields in bacteria. Read the full article at the PNAS website.
Related Faculty:
Efficient learning of decision-making models: A penalty block coordinate descent algorithm for data-driven inverse optimization
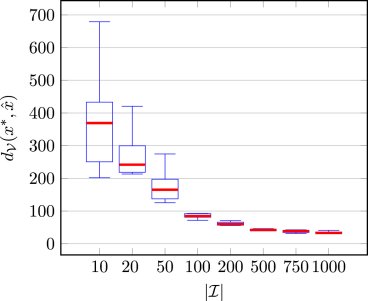
Decision-making problems are commonly formulated as optimization problems, which are then solved to make optimal decisions. In this work, we consider the inverse problem where we use prior decision data to uncover the underlying decision-making process in the form of a mathematical optimization model. Read the full article at ScienceDriect's website.
Related Faculty:
Dissipativity learning control (DLC): A framework of input–output data-driven control - ScienceDirect
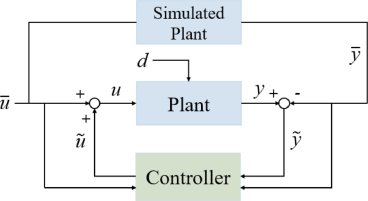
The paper addresses data-driven control based on input–output data in the absence of an underlying dynamic model. It proposes a dissipativity learning control (DLC) framework which involves the data-based learning of the dissipativity property of the control system. Read the full article at ScienceDirect's website.
Related Faculty: